
在上一篇文章《从附加功能到重构产品价值,端侧AI将重新定义可穿戴设备》中曾提到过智能终端正在利用本地侧AI来提升终端产品附加值,并逐步通过软硬件协同将AI从“附加功能”推向“重构核心能力”,转移设备价值重心,最终端侧AI将成为智能终端设备的定义者。
从生成式AI的云端智能到端侧AI落地的革命漫长的技术周期里,上下游厂商不断探索着硬件创新、端侧算法模型优化与场景落地的协同。那当AI走出云端落到端侧如何才能让终端设备真正“智能”?Deepseek的横空出世给出了一份答案。Deepseek展现的“低成本、高性能、开源”颠覆性优势,直接点亮了终端侧AI的发展前景,端侧智能不再完全受限于硬件算力与能效,大模型通过蒸馏技术重构的小模型在端侧部署可行性大增。
从已发布的多个Deepseek R1的精简模型来看,在保持性能的前提下,能将模型参数量大幅压缩,这使得端侧模型部署难度显著减小,并突破以往端侧AI面临存储空间、算力消耗、推理延迟等部署障碍。知名分析师郭明錤日前也发文指出,Deepseek爆红后,端侧AI趋势将加速。
端侧应用的想象空间的确在Deepseek的加持下不断扩大,特别是在今年端侧AI元年这个时间节点,AI模组厂商纷纷布局Deepseek,帮助下游终端客户搭建本地智能。模组与Deepseek的融合,这意味着产业链下游的中小型厂商能够通过模组快速集成AI能力推出各自的终端产品。可以说AI模组正在破局DeepSeek在实体产业落地的最后一公里,AI也将在今年快速向终端普及。
Deepseek正在成为端侧AI新引擎
自Deepseek成为整个科技圈关注的焦点,上到芯片厂商、模组厂商下到软件厂商、方案厂商以及再到垂直应用的终端厂商,都在争先恐后加入Deepseek生态圈。这一全球现象级的模型到底有何特别之处,特别对于端侧应用来说,Deepseek给出了哪些不同以往模型的支持?
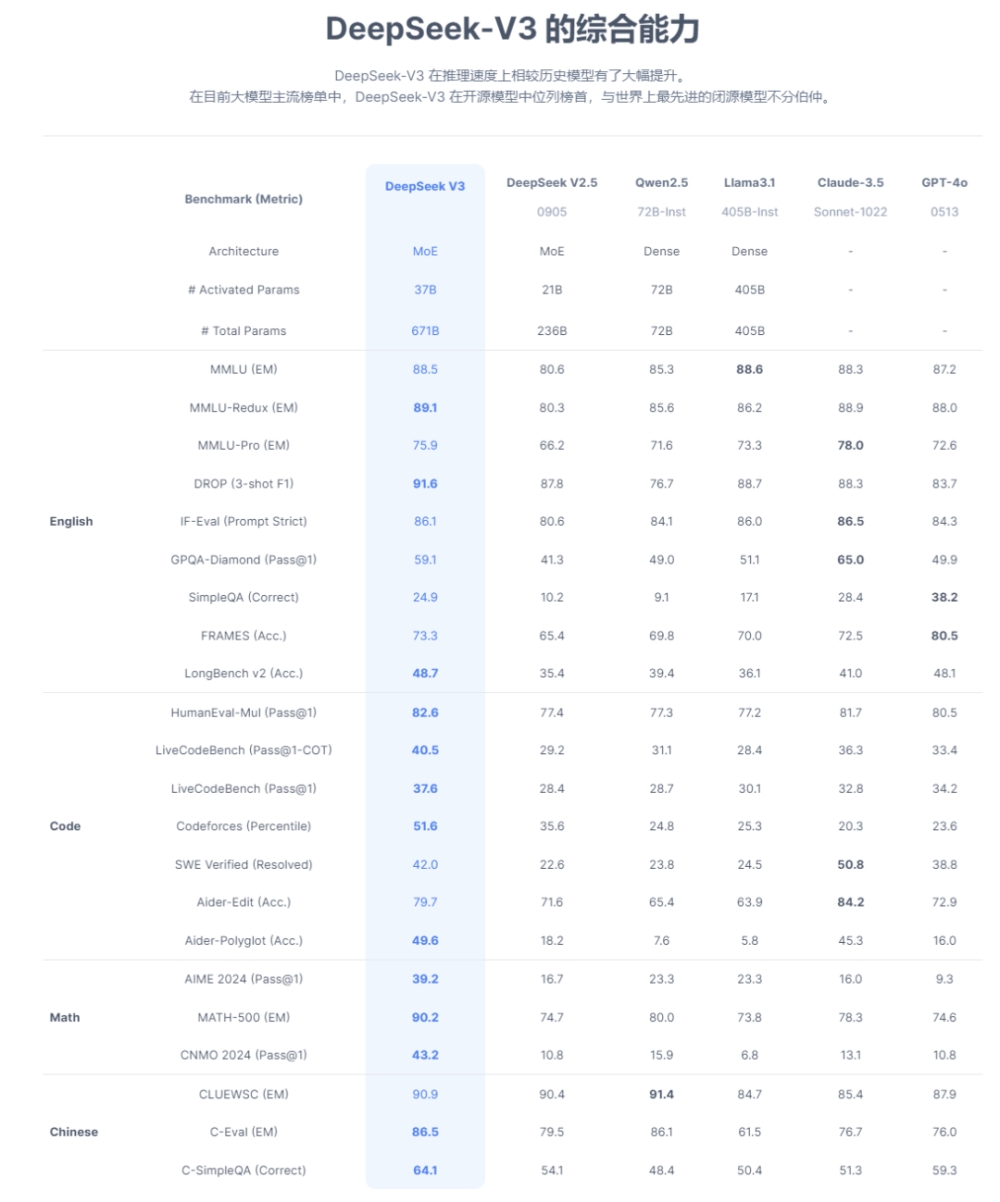
图源:Deepseek
首先是模型的轻量化设计,Deepseek采用自研的DeepseekMoE架构,和传统的MoE架构相比,减少专家间的知识冗余,并通过稀疏混合专家(Sparse Mixture of Experts)层替代传统Transformer的前馈网络(FFN),每个Token仅激活少量专家,大幅减少计算量和显存占用。
这一轻量化设计最直接的体现就是671B参数的模型实际激活参数量仅37B,显著降低推理资源需求。这意味着AI能够在计算资源有限的终端设备上运行,支持从超大规模模型到端侧设备的无缝扩展,在手机、PC、ARVR等可穿戴设备、汽车等端侧硬件本地化部署上具有很强的可操作性。
其次,大模型推理过程KV 机制是限制推理效率的一大瓶颈,Deepseek创新的MLA机制通过低秩联合压缩键值(KV)缓存,相比传统MHA减少约90%的KV缓存量,提升推理效率。MLA在保持性能的同时,减少对显存带宽的依赖,实现更彻底的轻量化,更适合端侧设备部署。
在模型蒸馏和本地部署上,Deepseek本身就提供了不少蒸馏版模型,如R1的1.5B版本,全面支持在资源受限硬件中运行。例如PC仅需1.1GB内存即可完成基础推理任务,极大扩展了AI的应用场景。
第二是Deepseek在低功耗上的优化。在并行计算与通信优化上大幅减少了功耗。Deepseek采用DualPipe流水线并行技术,通过重叠前向传播与后向传播的计算和通信阶段,减少GPU闲置时间。同时结合16路流水线并行、64路专家并行与ZeRO-1数据并行,能显著降低能耗。
Deepseek还支持FP8混合精度训练,对激活和权重分别采用Group-wise与Block-wise量化策略,在TensorCore上执行高效矩阵运算,减少计算能耗。推理阶段通过预填充与解码分离策略,优化资源分配。
最后是端侧看重的且相比云端更具优势的隐私保护机制。Deepseek支持完全离线的本地部署模式,用户数据无需上传云端,避免敏感信息泄露风险。
在加密与权限控制上,Deepseek采用动态路由策略与冗余专家部署,结合访问控制机制,防止模型内部数据被逆向分析。同时,API服务支持密钥管理与用量监控,进一步保障数据安全。
总的来看,Deepseek通过MoE架构和MLA注意力机制轻量化得更彻底且性能强劲,比依赖量化后模型体积缩减的TensorFlow Lite和依赖Metal加速与硬件适配的Core ML更灵活效率更高。加之低功耗与隐私保护方面的增强,这些革新的优势点都是端侧AI亟需的,推动了模型向端侧设备普及,也为AI落地的多元化需求提供了更优解,完全可以说Deepseek正在成为端侧AI的新引擎。
Deepseek带动端侧AI产业链发展
Deepseek虽然面世不久,但已经成为端侧AI上下游厂商的布局重点。在具体的端侧设备领域,手机方面包括OPPO、荣耀、魅族等厂商均宣布已经完成了对Deepseek模型的接入;汽车圈也开始全面适配,包括吉利、极氪、岚图、宝骏、智己、东风、零跑、长城等8家车宣布接入Deepseek;PC方面,国产GPU厂商沐曦与联想合作推出的Deepseek智能体一体机、英特尔AIPC合作伙伴Flowy在最新版的AIPC助手上率先支持了端侧运行Deepseek模型……终端硬件与Deepseek的融合正在以惊人的速度发展。

在上游芯片领域,花旗分析师Laura Chen团队在最近的研报中表示,Deepseek的出现推动AI技术的低成本化和端侧化,将重塑半导体行业格局。和模型息息相关的AI芯片产业链,国内企业正纷纷响应,沐曦、燧原科技、华为昇腾、海光信息、龙芯中科、天数智芯、壁仞科技、摩尔线程、中星微、云天励飞等十几家本土AI芯片厂商均宣布在云端或是端侧适配Deepseek模型。
如华为昇腾已与Deepseek合作,支持Deepseek-R1和Deepseek-V3模型的推理部署;云天励飞已经完成DeepEdge10“算力积木”芯片平台与Deepseek-R1系列大模型的适配,主攻端侧应用;海光信息宣布完成Deepseek V3和R1模型、Deepseek-Janus-Pro多模态大模型与海光DCU(深度计算单元)的适配;中星微技术旗下星光智能系列AI芯片也在全面融合Deepseek模型能力向端侧发力。
在智能硬件中成本占比最高的一环,端侧SoC以及ASIC芯片,随着Deepseek相关端侧应用爆发,在终端AI部署中的应用需求会增加,将迎来更多市场机会。如恒玄科技、瑞芯微、晶晨股份、全志科技、富瀚微、乐鑫科技、中科蓝讯、炬芯科技等公司的SoC芯片,翱捷科技、寒武纪等公司的端侧ASIC产品都较有代表性。
随着Deepseek模型在应用端的落地,智能终端对存储芯片的需求同样强烈。以典型的端侧AI与先进存储技术代表终端AI手机为例,一部高端机型需要搭载8-12GB的DRAM和128-512GB的NAND Flash。可穿戴市场上对中大NOR Flash容量需求增加也是确定性的趋势,尤其是中大容量NOR Flash。兆易创新、江波龙、普冉股份、恒烁股份等存储芯片厂商也在端侧AI时代同样能一展身手。
模组厂商也在迅速推进端侧AI加Deepseek方面的融合,如美格智能正在加速开发DeepSeek-R1在端侧的落地应用,并计划在2025年推出100TOPS级别的AI模组;广和通、移远通信、润欣科技、芯讯通等厂商也在推进相关模组产品布局。

移远通信已经宣布其搭载高通 QCS8550 平台的边缘计算模组 SG885G,成功实现了 DeepSeek-R1 蒸馏小模型的稳定运行,在成功实现 DeepSeek 模型端侧运行;广和通不久前已官宣高算力 AI 模组及解决方案全面支持小尺寸的 DeepSeek-R1 模型,帮助客户快速增强终端 AI 推理能力;美格智能正在结合 AIMO 智能体、高算力 AI 模组的异构计算能力,结合多款模型量化、部署、功耗优化 Know-how,加速开发 DeepSeek-R1 模型在端侧落地应用及端云结合整体方案……

端侧AI已经成为推动智能设备革新的核心力量,Deepseek风暴为这个即将迎来爆发的市场向前推进推进了一大步。端侧AI+Deepseek带来的终端全面AI正在加速到来,产业链上下游也将在这波浪潮中受益良多。
Deepseek推动端侧AI元年到来,AI模组破局Deepseek在端侧实体产业落地的最后一公里
回到开头的问题,当AI走出云端落到端侧如何才能让终端设备真正“智能”?从目前的端侧应用来看,Deepseek正在破解端侧AI落地最后一公里面对着硬件碎片化、模型泛化性、以及端侧能效三个难题。
硬件碎片化即不同端侧设备如手机、摄像头、传感器的算力差异大、架构差异大,传统AI模型难以高效适配统一优化。这方面Deepseek带来的改变已经开始显现,首先通过Deepseek蒸馏和量化出来的端侧模型已经做到了和硬件无关的轻量化,支持从超大规模模型到端侧设备的无缝扩展,解决了一部分端侧场景多层次硬件需求。
其次通过优化模型架构,Deepseek的动态异构计算框架支持端侧芯片内多种计算单元的协同调度来解决硬件配置碎片化难题。这一方面目前各上游芯片原厂已经开始全面推进基于Deepseek的软硬协同创新,相信后续出来的端侧芯片能很好地解决不同端侧设备算力差异大、架构差异大的问题。
模型泛化性即传统模型易受多变的端侧环境干扰,如何在保证端侧轻量化的同时,让模型适应端侧场景的复杂多变。Deepseek给出的答卷也很出彩,其跨维度知识蒸馏体系将大模型的逻辑解构为思考推理,而非单纯知识记忆,再通过动态权重分配注入端侧模型。端侧模型虽小但较以往的端侧模型性能更优,更全面地适配端侧垂直场景。
至于端侧能效,长期以来都是模型算法厂商与端侧硬件设备厂商在攻克的命题,这需要两边长期的软硬协同优化。Deepseek在算法层面已经做了极致的压缩,如何与硬件做定制化的协同优化就看后续的适配与迭代了。
Deepseek的出现加速了端侧AI发展进程,而AI模组与Deepseek的融合为端侧实体产业落地的最后一公里提供了一条破局之道。对于端侧AI产业链下游的终端厂商来说,特别是中小型厂商,如何便捷快速高效地为终端产品赋予本地智能是一道难题。
Deepseek带动的资本市场热潮褪去后,落地到真正的实体产业带动终端设备升级与市场增长是下一阶段的关键。作为与终端设备关系最紧密的中游模组厂商,将AI模组与Deepseek的融合,为下游提供更精准、更高效的端侧AI产品与服务,为端侧实体产业落地的难题提供了解题思路。
Deepseek能够无缝地将大模型的推理能力迁移到更小、更高效的端侧版本中,也能更方便将其融合在智能模组中。像移远通信AI模组 SG885G成功实现了 在DeepSeek-R1 蒸馏小模型端侧运行的基础上,同时完成该模型的针对性微调,提供更精准、更高效的端侧 AI 服务,生成速度超过40Tokens/s,而且还能优化。此芯科技在端侧平台适配的DeepSeek-R1-1.5B模型推理速度接近40Tokens/s,7B模型达10Tokens/s。这表明端侧模组引入DeepSeek后,在推理速度提升上实现了显著升级。搭载DeepseekAI模组的端侧AI产品进而也能够承担更多计算量,减轻云端服务器的计算负担。
目前已经官宣跑通Deepseek的模组,在应用场景覆盖性很广,涵盖智能汽车、机器视觉、PC、机器人、智能家居、AI玩具及可穿戴设备等多元化场景,多场景应用支持让不同行业不同终端的下游设备厂商能够全面受益于Deepseek带来的本地智能,加速终端智能化的发展。
而且模组厂商正在大力推进不同算力、功耗的Deepseek模组产品,满足下游客户对成本、尺寸的差异化需求。模组针对不同终端应用持续的优化将大幅缩短端侧智能相关产品的落地周期,从而赋能终端侧真正享受到 AI 带来的收益。
Deepseek在解决了端侧AI硬件碎片化、模型泛化行和效能瓶颈上提供了强大助力,模组与Deepseek的深度结合更为端侧AI落地最后一公里难题指出了一条破局之道。这条破局之道指向的最终蓝图,是让端侧AI成为终端设备核心功能的定义者,让终端硬件真正智能起来。
写在最后
很长一段时间端侧模型都是制约智能终端硬件发展的枷锁,而现在DeepSeek的出现让这种局面开始有所好转。在可预期的未来里,针对端侧应用开发的Deepseek AI模组将涌现,为终端提供便捷高效的AI能力,端侧AI已处在爆发前夕。
