企业在开发及实施大模型应用过程中,面临四大挑战:
● 首先,数据准备时间长,数据来源分散,归集慢,预处理百TB数据需10天左右;
● 其次,多模态大模型以海量文本、图片为训练集,当前海量小文件的加载速度不足100MB/s,训练集加载效率低;
● 第三,大模型参数频繁调优,训练平台不稳定,平均约2天出现一次训练中断,需要Checkpoint机制恢复训练,故障恢复耗时超过一天;
● 最后,大模型实施门槛高,系统搭建繁杂,资源调度难,GPU资源利用率通常不到40%。
华为顺应大模型时代AI发展趋势,针对不同行业、不同场景大模型应用,推出OceanStor A310深度学习数据湖存储与FusionCube A3000训/推超融合一体机。

华为数据存储产品线总裁 周跃峰
OceanStor A310深度学习数据湖存储,面向基础/行业大模型数据湖场景,实现从数据归集、预处理到模型训练、推理应用的AI全流程海量数据管理。
OceanStor A310单框5U支持业界最高的400GB/s带宽以及1200万IOPS的最高性能,可线性扩展至4096节点,实现多协议无损互通。全局文件系统GFS实现跨地域智能数据编织,简化数据归集流程;通过近存计算实现近数据预处理,减少数据搬移,预处理效率提升30%。
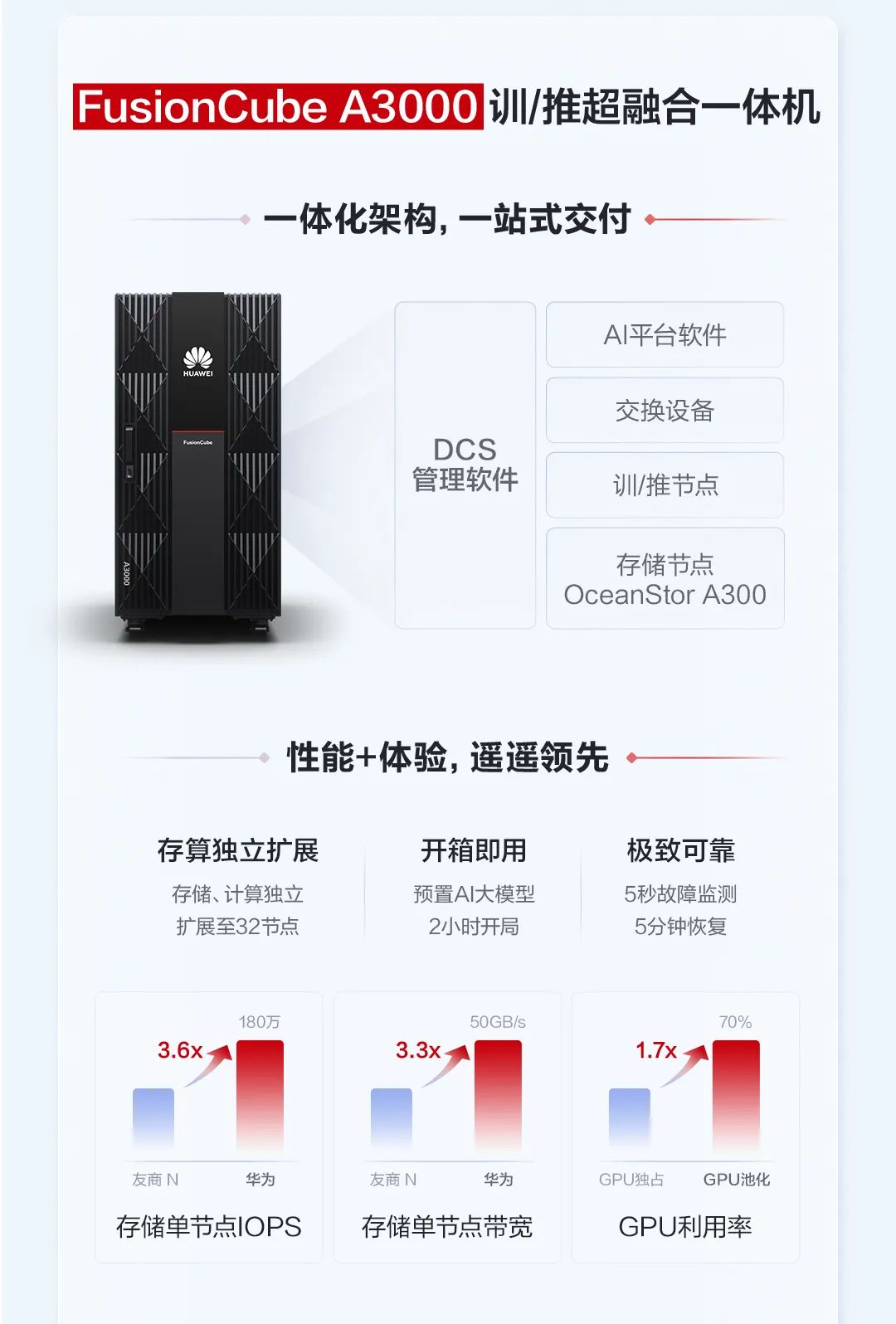
FusionCube A3000训/推超融合一体机,面向行业大模型训练/推理场景,针对百亿级模型应用,集成OceanStor A300高性能存储节点、训/推节点、交换设备、AI平台软件与管理运维软件,为大模型伙伴提供拎包入住式的部署体验,实现一站式交付。
FusionCube A3000开箱即用,2小时内即可完成部署。训/推节点与存储节点均可独立水平扩展,以匹配不同规模的模型需求。同时FusionCube A3000通过高性能容器实现多个模型训练推理任务共享GPU,将资源利用率从40%提升到70%以上。FusionCube A3000支持两种灵活的商业模式,包括华为昇腾一站式方案,以及开放计算、网络、AI平台软件的第三方伙伴一站式方案。
在本次活动中,中科院自动化所紫东太初大模型中心常务副主任、武汉人工智能研究院院长王金桥;科大讯飞副总裁、AI工程院院长潘青华;智谱AI算法工程师陶治华分别就AI大模型的应用实践以及基于华为AI存储的联合创新发表主题演讲。

中科院自动化所紫东太初大模型中心常务副主任
武汉人工智能研究院院长 王金桥

科大讯飞副总裁、AI工程院院长 潘青华

智谱AI算法工程师 陶治华
华为数据存储产品线总裁周跃峰表示:大模型时代,数据决定AI智能的高度。作为数据的载体,数据存储成为AI大模型的关键基础设施。华为数据存储未来将持续创新,面向AI大模型时代提供多样化的方案与产品,携手伙伴共同推进AI赋能千行百业。
下滑了解更多发布会精彩内容