
接触过基础计算机科学课程的朋友们,肯定都曾亲自动手设计排序算法——也就是借助代码将无序列表中的各个条目按升序或降序方式重新排列。这是个有趣的挑战,可行的操作方法也多种多样。人们曾投入大量时间探索如何更高效地完成排序任务。
作为一项基础操作,大多数编程语言的标准库中都内置有排序算法。世界各地的代码库中使用了许多不同的排序技术和算法来在线组织大量数据,但至少就与 LLVM 编译器配套使用的 C++库而言,排序代码已经有十多年没有任何变化了。
近日,谷歌 DeepMind AI 小组如今开发出一种强化学习工具 AlphaDev,能够在无需通过人类代码示例做预训练的情况下,开发出极限优化的算法。如今,这些算法已经集成到 LLVM 标准 C++ 排序库中,这是十多年来排序库部分第一次发生变化,也是第一次将通过强化学习设计的算法添加到该库中。
把编程过程视为“游戏”
由于不必预先接触任何人类游戏策略,DeepMind 系统往往能发现人类从未设想过的攻关思路。当然,由于完全依靠自我对抗来学习经验,DeepMind 在某些情况下也会形成可被人类利用的盲点。
这种方法跟编程其实非常相似。大语言模型之所以能够编写出有效代码,就是因为它们看到过大量人类代码示例。但也正因为如此,语言模型很难产出人类之前没做过的东西。如果我们希望对普遍存在的现有算法(例如排序函数)做进一步优化,那么继续依赖现有人类代码将很难突破固有思路的束缚。那么,如何才能让 AI 找到真正的新方向?
DeepMind 的研究人员采用了与国际象棋和围棋相同的方法:把代码优化任务转化成单人“组装游戏”。AlphaDev 系统开发出一种 x86 汇编算法,会将代码的运行延迟视为一个分数,在努力将该分数最小化的同时确保代码能够顺畅跑通。通过强化学习,AlphaDev 逐渐具备了编写紧凑、高效代码的能力。
AlphaDev 基于AlphaZero。DeepMind 向来以开发能自学游戏规则的 AI 软件而闻名。这种思路被证明效果拔群,也先后攻克了国际象棋、围棋和《星际争霸》等诸多游戏难题。虽然具体细节因所玩游戏而异,但 DeepMind 软件确实能在重复游玩中不断学习,持续探索能令得分最大化的办法。
AlphaDev 的两个核心组件是学习算法和表示函数。
AlphaDev 学习算法可以结合 DRL 和随机搜索优化算法来玩组装游戏。AlphaDev 中的主要学习算法是 AlphaZero 33的扩展,AlphaZero 33 是一种著名的 DRL 算法,其中训练神经网络以指导搜索完成游戏。
表示函数,负责跟踪代码开发时的整体性能,其中包括算法的常规结构以及对 x86 寄存器和内存的使用。该系统会单独添加汇编指令,通过蒙特卡洛树搜索(同样是一种从游戏系统中借用的方法)进行选择。树状结构允许系统快速将搜索范围缩小至包含大量潜在指令的有限区域,而蒙特卡洛方法则以一定程度的随机性从这个分支区域内选择具体指令。(请注意,这里所说的“指令”是为创建有效、完整程序集而选择特定寄存器等操作。)
之后,系统会评估汇编代码的延迟和有效性状态,为其打分并与前一次得分进行比较。而通过强化学习,系统会在给定的程序状态之下保留树结构中不同分支的工作信息。随着时间推移,系统将逐渐“学会”如何以最高得分(代表最低延迟)获得游戏胜利(成功完成排序)。 AlphaDev 的主要表示函数基于 Transformer。
为了训练 AlphaDev 发现新算法,AlphaDev 在每轮中都会观察它生成的算法和中央处理器 (CPU) 中包含的信息,然后通过选择要添加到算法中的指令完成游戏。AlphaDev 必须有效地搜索大量可能的指令组合,以找到可以排序的算法,并且还要比当前最好的算法更快,同时代理模型可以根据算法的正确性和延迟获得奖励。
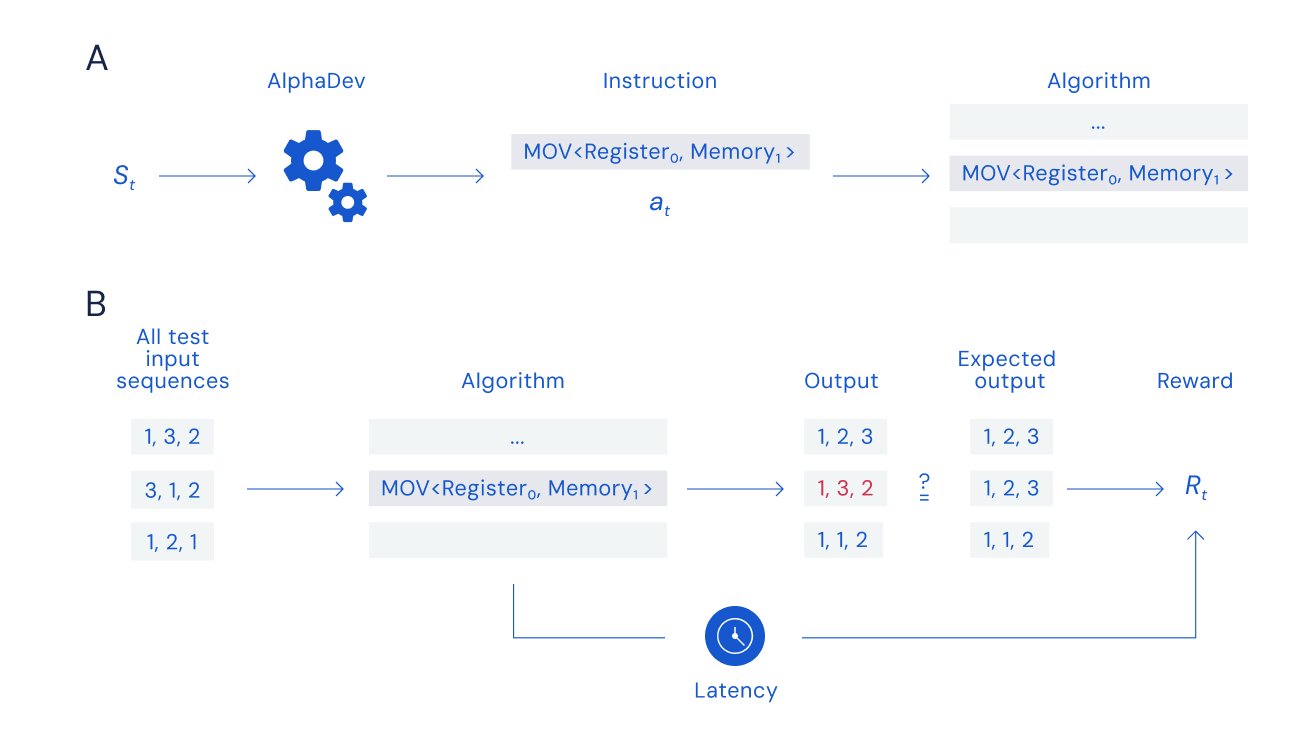
图 A:组装游戏,图 B:奖励计算
最终,AlphaDev 发现了新的排序算法,这些算法可以让 LLVM libc++ 排序库得到改进:对于较短的序列,排序库的速度提高了 70%;对于超过 250,000 个元素的序列,速度提高了约 1.7%。
具体而言,该算法的创新主要在于两种指令序列:AlphaDev Swap Move(交换移动)和 AlphaDev Copy Move(复制移动),通过这两个指令,AlphaDev 跳过了一个步骤,以一种看似错误但实际上是捷径的方式连接项目。
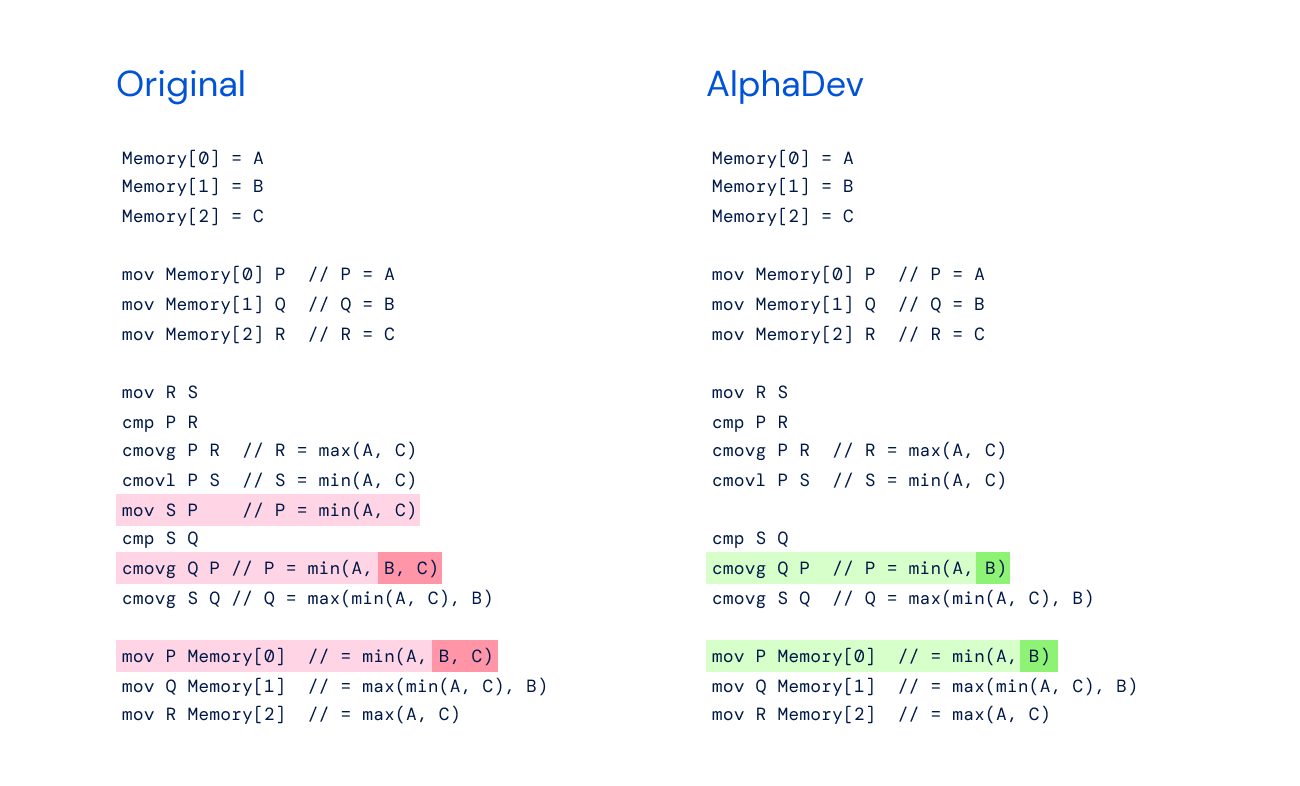
左图:带有 min(A,B,C) 的原始 sort3 实现。
右图: AlphaDev Swap Move - AlphaDev 发现你只需要 min(A,B)。
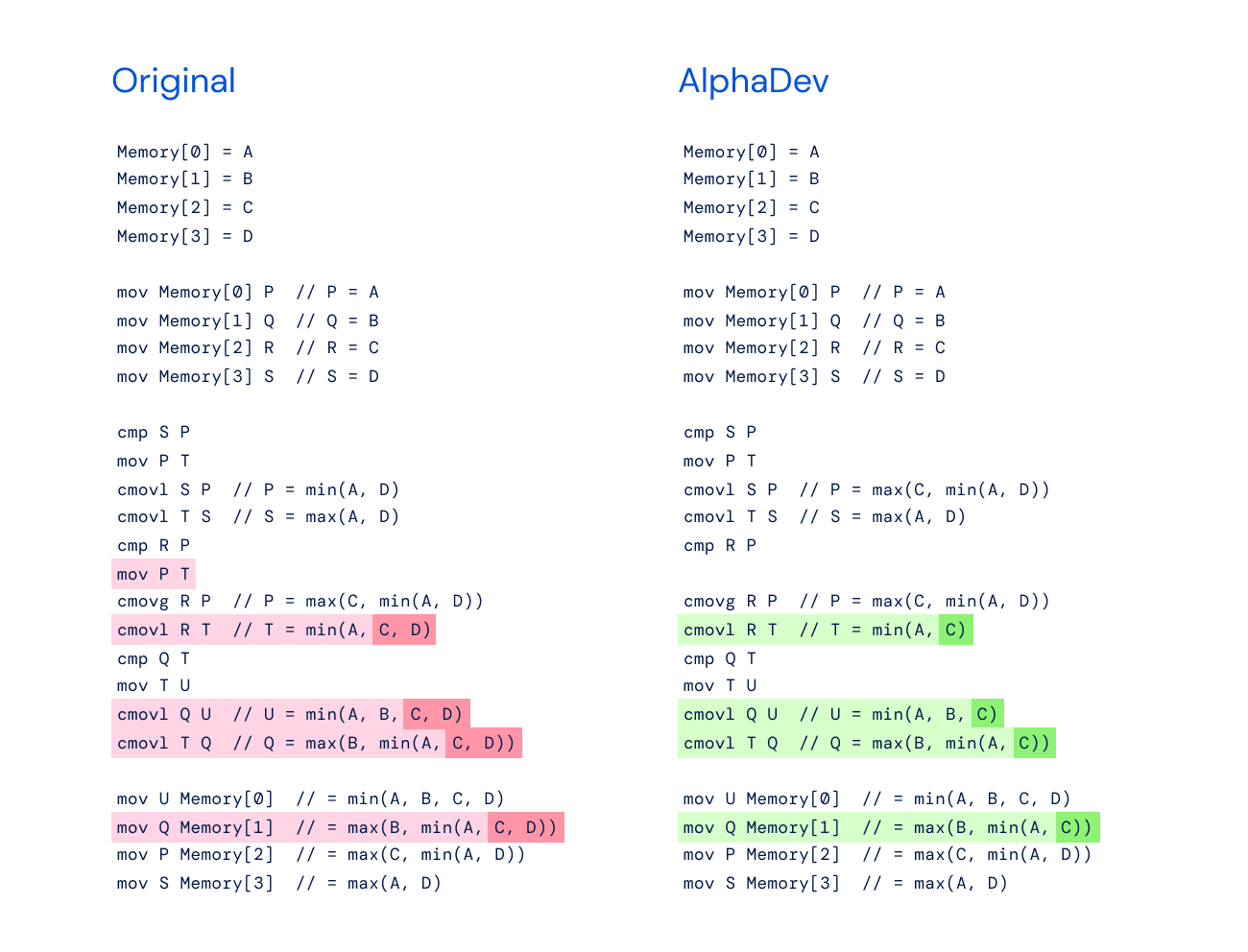
左:max (B, min (A, C))的原始实现用于对八个元素进行排序的更大排序算法。
右: AlphaDev 发现在使用其复制移动时只需要 max (B, min (A, C))。
这套系统的主要优势在于,其训练过程不借助任何代码示例。相反,系统会自主生成代码示例,然后对其做出评估。过程当中,它也就逐渐掌握了关于有效排序的指令组合信息。
从排序到散列
在发现更快的排序算法后,DeepMind 测试了 AlphaDev 是否可以概括和改进不同的计算机科学算法:散列。
哈希是计算中用于检索、存储和压缩数据的基本算法。就像使用分类系统来定位某本书的图书管理员一样,散列算法可以帮助用户知道他们正在寻找什么以及在哪里可以找到它。这些算法获取特定密钥的数据(例如用户名“Jane Doe”)并对其进行哈希处理——这是一个将原始数据转换为唯一字符串(例如 1234ghfty)的过程。计算机使用此散列来快速检索与密钥相关的数据,而不是搜索所有数据。
DeepMind 将 AlphaDev 应用于数据结构中最常用的散列算法之一,以尝试发现更快的算法。当将其应用于散列函数的 9-16 字节范围时,AlphaDev 发现的算法速度提高了 30%。
今年,AlphaDev 的新哈希算法被发布到开源Abseil 库中,可供全球数百万开发人员使用,该库现在每天被数万亿次使用。
实际可用的代码
复杂程序中的排序机制能够处理大量任意条目的集合。但在标准库层面来看,这种能力源自一系列高度限定的具体函数。这些函数各自只能处理一种或几种情况。例如,某些单独算法只能对 3、4 或 5 个条目做排序。我们也可以同时使用一组函数对任意数量的条目作排序,但原则上每一次函数调用最多只能对 4 个条目做排序。
DeepMind 在每个函数上都设置了 AlphaDev,其实际运行方式有着很大区别。对于负责处理特定数量条目的函数,可以编写出不含任何分支的代码,即根据变量状态执行不同的代码。因此代码性能往往与所涉及的指令数量成反比。
AlphaDev 已经成功将 sort-3、sort-5 和 sort-8 的指令数量各减一,在 sort-6 和 sort-7 中的指令削减量甚至更多。只有 sort-4 上没能找到改进现有代码的方法。而在实际系统上的重复运行测试证明,更少的指令确实带来了更好的性能。
至于对可变数量条目进行排序,则要求代码中包含分支,而不同处理器专用于处理这些分支的元件数量也有区别。
对于这类情况,研究人员在 100 台不同的计算设备上对代码性能做出了评估。AlphaDev 在这类场景下同样找到了进一步榨取性能的方法,下面我们以一次最多排序 4 个条目的函数为例,看看它到底是怎么操作的。
在 C++库的现有实现中,代码需要进行一系列测试来确认具体需要对多少个条目做排序,再根据条目数量调用相应的排序函数。
而 AlphaDev 修改后的代码则采取更加“神奇”的思路:它先测试是不是 2 个条目,如果是则调用相应函数立即做排序。如果数量大于 2 个,则代码会先对前 3 个条目做排序。这样如果确实只有 3 个条目,则返回排序结果。 由于实际是有 4 个条目要做排序,所以 AlphaDev 会运行专门代码,以非常高效的方式将第 4 个条目插入到前 3 个已经排序完成的条目中的适当位置。
这种办法听起来有点怪异,但事实证明其性能确实始终优于现有代码。
由于 AlphaDev 确实生成了更高效的代码,所以研究团队打算把这些成果重新合并到 LLVM 标准 C++库中。但问题是这些代码为汇编格式,而非 C++。所以他们必须通过逆向计算找到能够生成相同程序集的 C++代码。
现如今,代码成果已经被合并至 LLVM 工具链内,成为十多年来这部分代码的首次更新。 研究人员估计,AlphaDev 生成的新代码正每天被执行数万亿次。
结束语
“太棒了!将我们程序员很早就学会的这种基本排序任务的速度提高了 70%。看到 AI 在我们都依赖的算法和库中提供重大加速,真是令人兴奋。”有开发者对谷歌 DeepMind 的成果表示振奋。
但也有开发者并不买账:“相当令人失望……1.7% 的改善?5 个元素的序列 70%?可能是最不受欢迎、最不切实际的应用研究……”也有开发者表示:“说发现了新算法是不是有点误导人?似乎更像是算法优化。无论如何这仍然很酷。”
参考链接:
https://arstechnica.com/science/2023/06/googles-deepmind-develops-a-system-that-writes-efficient-algorithms/
https://www.deepmind.com/blog/alphadev-discovers-faster-sorting-algorithms
本文转载来源:
https://www.infoq.cn/news/IF32PWjiACV0aPxQGD70
