我们从一开始就说过,开放计算项目( Open Compute Project)的发起者 Meta Platforms 不可能想从 Nvidia 购买完整的超级计算机系统,以推进其人工智能研究并将更新的大型语言模型和推荐引擎投入生产。以 Facebook 为核心平台的 Meta Platforms 喜欢设计和构建自己的东西,但由于缺乏兼容 OAM 的 GPU 和矩阵加速器而措手不及,他们别无选择,只能购买使用InfiniBand模式互连的 N-1 代 DGX SuperPOD系统。
现在,当 Meta Platforms 展望社交网络内人工智能的未来以及支撑计算引擎的互连时,他们意识到,必须以令人难以置信的规模结合在一起,才能与超大规模和云构建器竞争对手竞争,于是,他们又将目光投向了以太网互连(Ethernet interconnects)。这就是为什么Meta Platforms 成为超以太网联盟( Ultra Ethernet Consortium)的创始公司之一。
这个联盟是由以太网 ASIC 供应商和交换机制造商组成的组织,他们并不是真的想相互合作,而是在受到互联网巨头及其新的人工智能新贵竞争迫使的情况下,他们想去找到一种方法,让以太网可以与InfiniBand一样好,也能像后者一样适用于 AI 和 HPC 网络,但使其扩展到其运行所需的规模。
对于今天的Meta Platforms来说,这意味着是大约 32,000 个计算引擎,然后是数十万台设备,然后在不久的将来的某些时候将超过 100 万台设备。
从当前看来,拥有这个想法的企业包括了交换机 ASIC 领域的 Broadcom、Cisco Systems 和 Hewlett Packard Enterprise(我们认为很快还有 Marvell),云巨头中的 Microsoft 和 Meta Platforms,以及交换机制造商中的 Cisco、HPE 和 Arista Networks。
他们正在团结在一起,面对一个共同的敌人——InfiniBand。他们的宗旨则是——敌人的敌人就是朋友。
归根到底,这是一条很简单的数学题。
InfiniBand很好,但也贵
在 21世纪的前十年,当超大规模企业和云构建商真正开始构建大规模基础设施时,任何分布式系统的网络部分(包括交换机、网络接口和电缆)只占整个系统成本的不到 10%。
而当第一代 100 Gb/秒设备问世时,由于设计不正确,成本非常高,很快网络成本就占到集群成本的 15% 或更多。随着价格实惠的 100 Gb/秒以太网的出现,以及现在速度达到 200 Gb/秒和 400 Gb/秒的速度,成本现在再次降至 10% 以下,但仅限于运行应用程序的前端网络。
对于超大规模企业和云构建者之间的人工智能训练和推理基础设施,Nvidia 会简单明了地告诉您,网络占集群成本的 20%。Nvidia 联合创始人兼首席执行官黄仁勋解释说:“InfiniBand 在相同带宽下的大规模性能比以太网高出 20%,因此“InfiniBand 实际上是免费的。”
但事实上,它(指代InfiniBand)不是免费的。你仍然需要拿出现金,而且它占集群成本的 20%。大家都知道GPU 计算引擎的成本非常高,但与基于 CPU 的 Web 基础设施集群的总体成本相比,这还是令人印象深刻的。人工智能系统的 InfiniBand 网络的成本,从节点到节点,肯定比在其他基础设施集群上运行数据库、存储和应用程序的以太网昂贵得多。当然,我们也承认,后者的带宽会相对较对。
虽然两大阵型都在彰显自己并攻击对方,但在650group看来,虽然以太网与 InfiniBand有很多争论,甚至有说法指出一种技术是如何以牺牲另一种技术为代价或消亡而取得成功的,存在,但这些争论都是错误的。
“以太网和 InfiniBand 各有优势,并且在同一市场中蓬勃发展。他们各有优劣势。”650group强调。
事实上,作为一种网络互联技术,InfiniBand以其高可靠性、低时延、高带宽等特点在超级计算机集群中得到广泛应用。此外,随着人工智能的进步,尤其是英伟达在GPU上的垄断,InfiniBand成为了GPU服务器的首选网络互连技术。

650group也指出,InfiniBand 有几个优点。首先,该技术已经存在 20 年,并且主要专注于 HPC 网络;其次,它是一项从一开始就为 HPC 和 AI 网络构建的技术‘第三,人工智能可以使用低延迟和协议内置的项目,例如网络内数据处理,这有助于进一步加速人工智能。一个很好的例子是 InfiniBand 的 SHARP 网内计算技术将 AI 数据缩减操作(AI 训练的关键要素)吞吐量提高了两倍,这使得 InfiniBand 成为 AI 平台性能最高的网络,并成为人工智能平台的领先解决方案。
以太网也是人工智能平台中领先的外部和管理网络。
自1980年9月30日推出以来,以太网标准已成为局域网中使用最广泛的通信协议。与 InfiniBand 不同,以太网的设计考虑了以下主要目标:信息如何在多个系统之间轻松流动?这是一个典型的具有分布式和兼容性设计的网络。传统以太网主要采用TCP/IP来构建网络,目前已逐渐发展为RoCE。
一般来说,以太网主要用于将多台计算机或其他设备(例如打印机、扫描仪等)连接到局域网。它不仅可以通过光纤电缆将以太网连接到有线网络,还可以通过无线组网技术实现无线网络中的以太网。快速以太网、千兆以太网、10 吉比特以太网和交换以太网都是以太网的主要类型。
博通资深VP Ram Velaga 几个月前在社交平台中更是指出,以太网速度一直比Infiniband快至少2倍。今天,以太网的速度为每秒800千兆位,而Infiniband的速度为400Gbps。他表示,在 Infiniband 上以 400Gbps 的速度完成 1MB 消息传输需要 20 微秒,而在以太网上以 800Gbps 的速度完成 10 微秒。
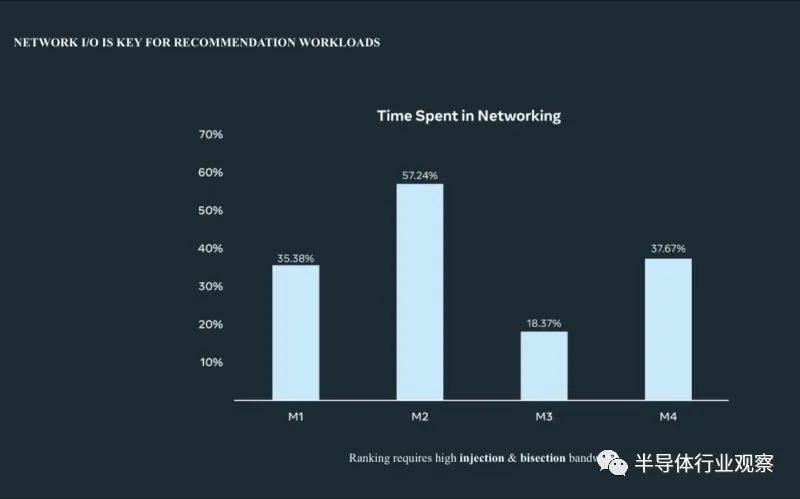
Meta的Alexis Black Bjorlin在 OCP 2022 上更是介绍了在网络中用于推荐工作负载的时间百分比。按照她的观点,用以太网取代Infiniband将使网络时间减少一半。这在整个AI基础设施上节省了10%-25%+的成本,且更可持续!
但即使如此,如前文所说,英伟达凭借在GPU的强势关系,他们已经在Infiniband的选择上拥有了更多地话语权。于是,Ultra Ethernet Consortium(超以太联盟,UCE)横空出世。
超以太联盟,卷土重来
之所以说是卷土重来,是因为这个联盟从某种意义上来说是为了完成以太网的未竟任务。
据白皮书介绍,超以太网联盟的目标是创建一个“完整的基于以太网的通信堆栈架构”,该架构将像以太网一样普遍且经济高效,同时提供超级计算互连的性能。该联盟的创始成员包括文章开头谈到的那些积极参与 HPC 和网络的公司,包括英特尔、AMD、HPE、Arista、Broadcom、思科、Meta 和微软,该项目本身由 Linux 基金会托管。
UEC 主席 J Metz 博士在接受采访的时候告诉The Register,该项目的目标不是改变以太网,而是对其进行调整,以更好地适应 AI 和 HPC 工作负载更苛刻的特征。
“以太网是我们构建的基础技术,因为它是业界持久、灵活和适应性强的基本网络技术的最佳范例,”他说。“UEC 的目标是专注于如何在以太网上最好地承载 AI 和 HPC 工作负载流量。当然,之前已经有过一些尝试,但没有一个是针对高要求的 AI 和 HPC 进行全新设计的工作负载,但没有一个是开放的、易于使用的并赢得了广泛的采用。”他进一步指出。
针对网络堆栈的多个层,该项目工作组的任务是开发物理层和链路层的“增强性能、延迟和管理的规范”,以及开发传输层和软件层的规范。
根据白皮书,网络对于 AI 模型的训练变得越来越重要,而 AI 模型的规模正在不断膨胀。有些拥有数万亿个参数,需要在大型计算集群上进行训练,并且网络需要尽可能高效才能保持这些集群繁忙。
虽然 AI 工作负载往往非常需要带宽,但 HPC 还包括对延迟更加敏感的工作负载,并且需要满足这两个要求。为了满足这些需求,UEC 确定了以下理想特性:灵活的delivery顺序(flexible delivery order);现代拥塞控制机制(modern congestion control mechanisms);多路径和数据包扩散(multi-pathing and packet spraying);加上更大的可扩展性和端到端遥测(greater scalability and end-to-end telemetry)。
根据白皮书,旧技术使用的严格数据包排序会阻止无序数据直接从网络传递到应用程序,从而限制了效率。支持放宽数据包排序要求的现代 API 对于减少“尾部延迟”(tail latencies)至关重要。
多路径和数据包扩散涉及沿着源和目标之间的所有可用网络路径同时发送数据包,以实现最佳性能。
如果多个发送方都针对同一节点,则 AI 和 HPC 中的网络拥塞主要是交换机和接收节点之间的链路问题。然而,UEC 声称,当前管理拥塞的算法并不能满足针对人工智能优化的网络的所有需求。
首先,UEC 的目标似乎是用可提供所需特性的新传输层协议取代融合以太网上的 RDMA (RoCE) 协议。这种超以太网传输将支持多路径、packet-spraying传输、高效的速率控制算法,并向人工智能和高性能计算工作负载公开一个简单的 API——或者至少这是其意图。
HPE 对 UEC 的参与引人注目,因为它已经拥有基于以太网的 HPC 互连。正如The Next Platform的作者在文章中详细描述的那样,Cray Slingshot 技术是以太网的“超集” ,同时保持与标准以太网框架的兼容性,并且在 HPE 最近参与的许多超级计算机项目中得到了应用,例如Frontier 百亿亿次系统。
HPE 高性能互连总经理 Mike Vildibill 表示,该公司支持 UEC 的动机是希望确保 Slingshot 在开放的生态系统中运行。“我们希望符合 UEC 的 NIC 能够体验到 Slingshot 结构的一些性能和可扩展性优势,”他说。Vildibil 证实,HPE 未来将继续开发 Slingshot,但他认为总会有一些第三方 NIC 或 SmartNIC 可能具有其 Slingshot NIC 上未实现的功能。
“因此,UEC 提供了一种机制来建立强大的第三方 NIC 生态系统,以确保我们能够支持广泛的客户需求,同时提供 Slingshot 的一些独特功能,”他说。
目前,UEC 正处于开发的早期阶段,关键技术概念仍在确定和研究中。Metz 博士表示,第一批批准草案可能会在 2023 年底或 2024 年初准备就绪,第一批基于标准的产品也预计将于明年推出。
芯片厂商积极参与,Meta放了个大招
虽然UEC正在推进,但很多厂商正在通过其产品来打破英伟达的垄断。
以最积极的芯片厂商博通为例,今年夏天,Nvidia 承诺推出 Spectrum-X 平台,为生成型 AI 工作负载提供“无损以太网”。但博通的Ram Velaga 强调,这并不是新鲜事,英伟达的产品,也并没有什么特别之处是博通不具备的。
他解释说,Nvidia 使用 Spectrum-X 实际上所做的是构建一个垂直集成的以太网平台,该平台擅长以最小化尾延迟并减少 AI 作业完成时间的方式管理拥塞。但Velaga 认为,这与 Broadcom 对其Tomahawk5和Jericho3-AI交换机 ASIC所做的没有什么不同。他还认为 Nvidia 承认以太网对于处理人工智能中的 GPU 流更有意义。
我们需要稍微解析一下,Nvidia 的 Spectrum-X 不是产品。它是硬件和软件的集合,其中大部分我们在过去已经介绍过。核心组件包括Nvidia的51.2Tbit/s Spectrum-4以太网交换机和BlueField-3数据处理单元(DPU)。
其基本思想是,只要您同时使用 Nvidia 的交换机及其 DPU,它们就会协同工作以缓解流量拥塞,并且(如果 Nvidia 可信的话)完全消除数据包丢失。
虽然英伟达声称这是其全新的功能单元,但 Velaga 认为“无损以太网”的想法只是营销。“与其说它是无损的,不如说你可以有效地管理拥塞,从而拥有一个非常高效的以太网结构,”他说。换句话说,与以太网网络不同,数据包丢失是必然的,它是规则的例外。无论如何,这就是想法。
Velaga 声称,这种拥塞管理已经内置于 Broadcom 最新一代的交换机 ASIC 中 - 只是它们可以与任何供应商或云服务提供商的 smartNIC 或 DPU 配合使用。Velaga 还表示,Nvidia 试图实现的垂直整合与以太网是冲突的。
“以太网今天成功的全部原因是它是一个非常开放的生态系统,”他说。
作为以太网的另一个支持者, Meta Platforms近日也在其主办的 Networking Scale 2023 活动上展示了融合以太网上采用 RDMA 的以太网(一种借鉴了 InfiniBand 的许多想法的低延迟以太网)。
据nextplatform报道,该公司谈到了如何使用以太网进行中等规模的人工智能训练和推理集群,以及其近期计划如何扩展到具有 32,000 个 GPU 共享数据的系统,并使规模比它一直用于创建和训练 LLaMA 1 和 LLaMA 2 模型的最初 2,000 个 GPU 集群提高了16 倍。需要强调一下,Meta Platforms 从 Nvidia 购买的研究超级计算机系统最多拥有 16,000 个 GPU,其中大部分是 Nvidia 的“Ampere”A100 GPU,其中相对较小的份额是更新且容量更大的“Hopper”H100 模块。
“人工智能模型每两到三年就会增长 1,000 倍,”该公司网络基础设施团队软件工程总监 Rajiv Krishnamurthy 解释道。“我们在 Meta 内部观察到了这一点,我认为根据我们在行业中观察到的情况,这似乎是一种长期趋势。这个数字很难理解。因此,从物理角度来看,这会转化为数万个 GPU 集群大小,这意味着它们正在生成万亿次计算。这是由 EB 级数据存储支持的。”
“而从网络角度来看,您正在考虑操纵每秒大约太比特的数据。工作负载本身就很挑剔。由此人们了解到,典型的 AI HPC 工作负载具有非常低的延迟要求,而且从数据包的角度来看,他们无法容忍丢失。”Rajiv Krishnamurthy 说。
为此,Meta Platforms 希望用于 AI 训练的生产集群的规模比其 2022 年 1 月购买的 Nvidia RSC 机器的规模扩大 2 倍,并在去年全年不断扩大规模,达到 16,000 个 GPU 的完整配置。然后,不久之后,就会讨论 48,000 个 GPU,然后是 64,000 个 GPU,依此类推。
在Meta看来,构建一个可以进行 LLM 训练(目前在Meta Platforms 上使用 LLaMA 2)和推理以及 Reco 训练和推理(在本例中为自主开发的深度学习推荐模型或 DLRM)的系统非常困难,而且考虑到这四种工作负载的不同要求,这甚至可以说是不可能的,正如 Meta Platforms 人工智能系统部门的研究科学家 Jongsoo Park 在这个蜘蛛图中所示:

Park 表示,Meta Platforms 拥有 32,000 个 H100,在 FP8 四分之一精度浮点数学生产中产生约 30% 的峰值性能,Meta Platforms 将能够在一天内训练具有 650 亿个参数的 LLaMA2 模型。为了实现这一目标,很多事情都必须改变,其中包括将训练令牌(token)批次增加到 2,000 以上,并在数千个 GPU 上进行扩展。全局训练批量大小还必须在 32,000 个 GPU 上保持不变,并使用他所谓的 3D 并行性(数据并行、张量并行和管道并行技术的组合)将工作分散到 GPU 上。Park 表示,由于参数和数据量变得如此之大,数据并行性正在耗尽,因此没有办法解决这个问题。

为此,Meta一直在改个其系统,以满足客户需求。
在几年前,DLRM 训练和推理可以在单个节点上完成。然后,通过第一代以太网 RoCE 集群,Meta 可以将多个节点集群在一起,但集群规模相当有限。为了获得所需的规模,它必须转向 InfiniBand 和以太网 RoCE v2,前者存在财务问题,后者存在一些技术问题,但该公司到目前为止已经解决了。
Meta Platforms 担任网络工程师Lapukhov 表示,从基本构建模块开始,基于 Nvidia 加速器的八路 GPU 服务器可以在节点内具有数十个加速器的设备之间提供 450 GB/秒的带宽。模型并行流量在节点内互连上运行,在本例中为 NVLink,但也可以是 PCI-Express 交换基础设施。从这里开始,模型必须使用某种形式的 RDMA(InfiniBand 或以太网 RoCE)跨数千个节点(具有数万个聚合 GPU 计算引擎)进行数据并行扩展,并且您可以以 50 GB/秒的速度交付具有合理数量的网络接口卡的节点之间的带宽。
对于以太网 AI 网络,Meta Platforms 使用与数据中心规模前端网络应用程序相同的 Clos 拓扑,而不是在 AI 训练和 HPC 集群中使用 InfiniBand 的用户普遍青睐的fat tree 拓扑。
为了达到 32,256 个 GPU,该公司在一个机架中放置了两台服务器,每台服务器配有 8 个 Nvidia H100 GPU。就机架而言,这并不是特别密集,但它的密度并不比 Nvidia 本身对其 DGX H100 集群所做的密集。这意味着有 2,000 个机架需要连接,如下所示:
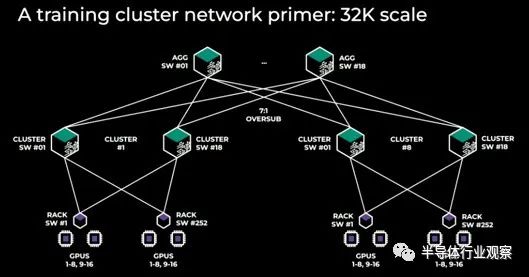
如果仔细观察,它实际上是 8 个集群,每个集群有 4,096 个 GPU,每个集群在两层网络中交叉链接。
每个机架都有一对服务器,总共有 16 个 GPU 和一个架顶交换机。目前尚不清楚服务器或交换机中有多少个端口,但每个 GPU 最好有一个上行端口,这意味着每台服务器有 8 个端口。(这就是 Nvidia 对其 DGX 设计所做的事情。)整个 enchilada 中总共有 2,016 个 TOR。随着网络的发展,交换机的数量相当多。
这些架顶交换机使用 18 个集群交换机(您可以称之为主干)交叉连接成一个集群,整个集群中有 144 个交换机。然后还有另外 18 个具有 7:1 超额订阅锥度的聚合交换机,将 8 个子集群相互链接。即 2,178 个交换机互连 4,032 个节点。由于这些数据密集型 GPU 的带宽需求,该比率为 1.85:1。
Lapukhov 的这张表很酷,它表明就 AI 模型而言,子集群粒度实际上约为 256 到 512 个 GPU:
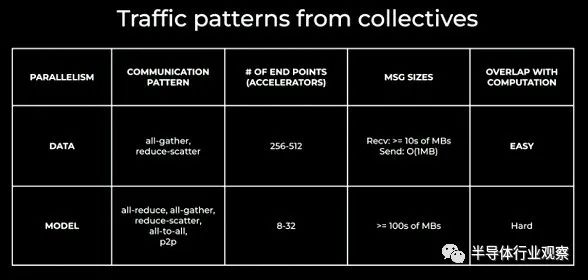
这显示了支撑人工智能的集体操作如何映射到网络上:
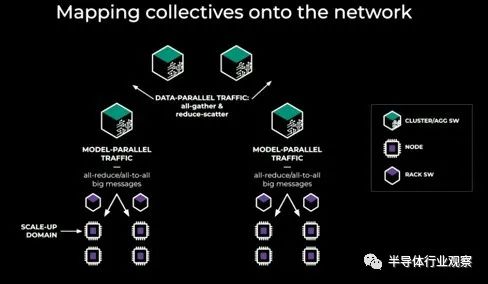
要点就是这样,这并不奇怪。当您制作更大的结构以跨越更多 GPU 时,您会向网络添加更多层,这意味着更多延迟,这会降低 GPU 的利用率,至少在 GPU 等待集体操作完成的某些时间在集群周围传播。但完全共享数据并行全收集操作往往会发送小消息(通常为 1 MB 或更小),如果您能够很好地处理小消息,则可以通过通信和计算的细粒度重叠来实现张量并行。
听起来好像有人需要大型 NUMA 节点来进行推理和训练。。。。这正是 NVLink 的作用和 NVSwitch 的扩展。
那么这在 Meta Platforms 数据中心中是什么样子的呢?那么,前端数据中心结构如下所示:
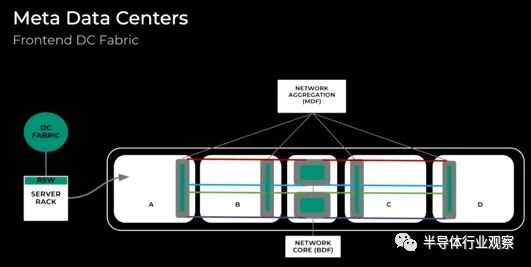
我们将数据中心划分为四个房间,每个房间都有一些聚合网络,然后核心网络将数据中心中心自己区域内的房间连接在一起。为了将人工智能添加到服务器机房,集群训练交换机(CTSW)和机架训练交换机(RTSW)与其他应用服务器添加到同一机房,并且可以与应用服务器交错。在四个数据大厅中,Meta可以容纳数以万计的紧密耦合的 GPU:
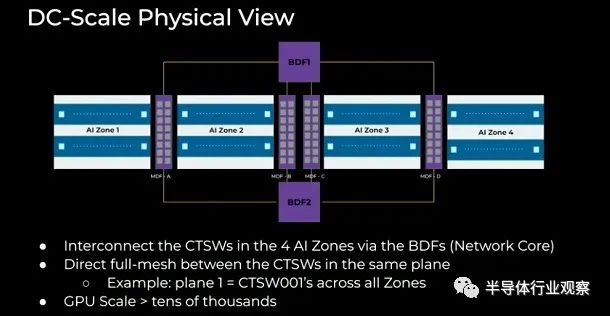
这是网络平面的 3D 表示(如果这样更容易可视化):
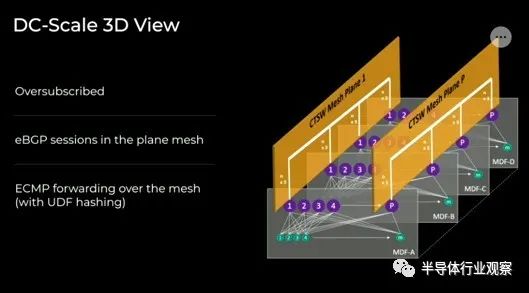
早在过去,Meta Platforms 使用 100 Gb/秒以太网和 RoCE v1 并取得了一些成功:
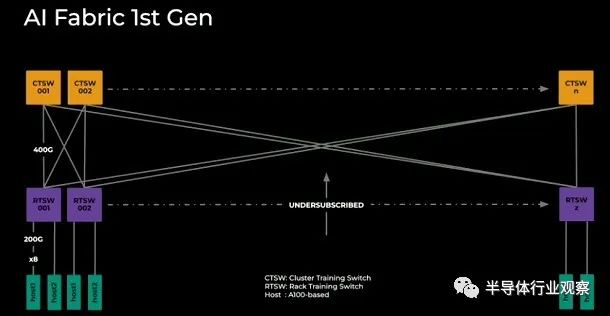
随着转向以太网 RoCE v2(延迟和数据包保护功能得到极大改善),Meta Platforms 将 8 个 200 Gb/秒的端口连接到每台服务器,并使用 400 Gb 将这些端口与机架和集群交换机交叉耦合/秒端口。
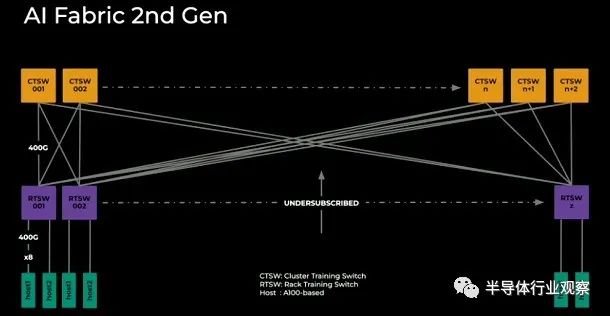
在第二代 AI 架构中,他们已将每个 GPU 的主机下行链路速度提升至 400 Gb/秒,并且仍在运行更高级别的网络订阅不足,无法保持比特顺利传输。
Nextplatform的作者认为,在未来的很多年里,情况都会如此。但如果超以太网联盟采用Neta的方式,以太网将更像 InfiniBand,并将拥有多个供应商,从而为所有超大规模提供商和云构建商提供更多选择和更大的竞争压力,以降低网络价格。
不过,不要指望它的成本会低于集群成本的 10%——只要 GPU 的成本仍然很高。但有意思的是,随着 GPU 成本的下降,来自网络的集群成本份额将会上升,从而给 InfiniBand 带来更大的压力。
参考链接
https://community.fs.com/blog/infiniband-vs-ethernet-which-is-right-for-your-data-center-network.html
https://www.nextplatform.com/2023/09/26/meta-platforms-is-determined-to-make-ethernet-work-for-ai/
https://www.theregister.com/2023/07/20/ultra_ethernet_consortium_ai_hpc/