作为最领先的大模型,GPT-4 有自我纠正生成代码的能力,结合人类反馈,自我纠正能力还能进一步的提高。
大型语言模型(LLM)已被证明能够从自然语言中生成代码片段,但在应对复杂的编码挑战,如专业竞赛和软件工程专业面试时,仍面临巨大的挑战。最近的研究试图通过利用自修复来提高模型编码性能。自修复是指让模型反思并纠正自己代码中的错误。
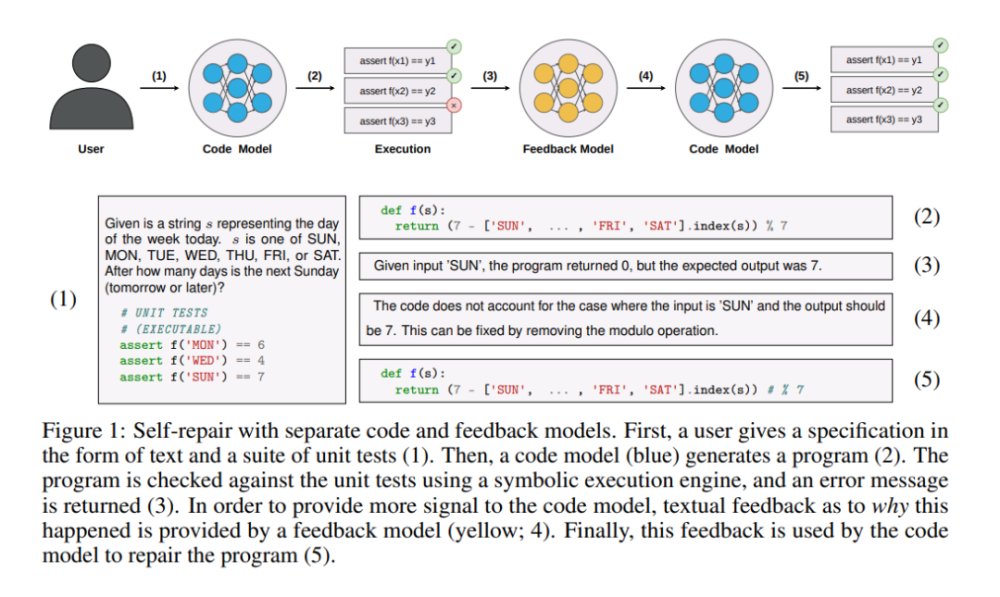
下图 1 显示了基于自修复方法的典型工作流程。首先,给定一个规范,从代码生成模型中对程序进行采样;然后在作为一部分规范提供的一套单元测试上执行程序;如果程序在任一单元测试中失败,则将错误消息和错误程序提供给一个反馈生成模型,该模型输出代码失败原因的简短解释;最后,反馈被传递给修复模型,该模型生成程序的最终固化版本。
从表面上看,这是一个非常有吸引力的想法。这种设计能让系统克服在解码过程中由离群样本引起的错误;在修复阶段,可以轻松地整合来自编译器、静态分析工具和执行引擎等符号系统的反馈,并模仿人类软件工程师编写代码的试错方式。
然而,自修复需要更多的模型调用,计算成本较高。特别要注意的是,自修复能否奏效,最终归结为在同等计算性能预算下,是否能从模型中抽取更多代码样本,并将其与作为一部分任务提供的单元测试套件进行比较。
至关重要的是,自修复的有效性不仅取决于模型生成代码的能力(文献中对此进行了广泛研究),还取决于它识别代码(由模型本身生成)在任务规范方面是如何出错的能力。此前没有任何工作试图详细研究这些能力的影响。
本文中,来自 MIT、微软研究院的研究者在解决竞赛级别的代码生成任务时,使用 GPT-3.5 和 GPT-4 研究自修复的有效性。研究者首先提出一种新的评估策略,称为 pass@t,其中获得正确程序的可能性(相对于给定的单元测试)相对于从模型中采样的 token 总数进行加权。
使用新的评估策略代替传统的 pass@k 度量(根据试验次数衡量通过率),研究者能够准确地将通过自修复获得的性能与模型在生成反馈和进行修复时所做的任何额外工作进行比较。研究者仔细探究了在一系列超参数下的动态自修复过程。
最后,鉴于研究的主要目标是深入了解最先进的代码生成模型反思和调试自己代码的能力,本文进行了一组实验,单独研究了改进反馈阶段的影响。通过分析使用比代码生成模型更强的反馈生成模型(使用 GPT-4 为 GPT-3.5 代码模型生成反馈)的影响,研究者进行了一项研究:让人类对不正确的程序提供反馈,以便将模型生成的自反馈与人类提供的自反馈进行比较。

论文地址:https://arxiv.org/pdf/2306.09896.pdf
从本文的实验中,研究者有了以下发现:
1. 当考虑进行检查和修复的成本时,自修复的性能收益只能用 GPT-4 来衡量;对于 GPT-3.5,在所有配置下,修复的通过率低于或等于基线模型 / 无修复方法的通过率。
2. 即使对于 GPT-4,性能提升也是适度的(66%→ 71% 的通过率,预算为 7000 个 token,约 45 个独立同分布(i.i.d.)的 GPT-4 样本),并同时取决于初始程序是否具有足够的多样性。
3. 用 GPT-4 产生的反馈代替 GPT-3.5 对错误的解释,可以获得更好的自修复性能,甚至超过了基线的无修复 GPT-3.5 方法(50%→ 7000token 时为 54%)。
4. 用人类的解释取代 GPT-4 自己的解释可以显著改善修复结果,从而使通过测试的修复程序数量增加 57%。
爱丁堡大学博士生符尧表示:「只有 GPT-4 可以自我改进,而较弱的模型不能,这一发现非常有趣,表明(大模型存在)一种新型的涌现能力(即改进自然语言反馈),可能只有在模型足够成熟(大而整齐)时才存在。大模型的这种能力在论文《Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback》中也存在过。
只有足够成熟的模型才能清楚(listen to)并改进自然语言反馈,较弱的模型要么无法理解反馈,要么无法对其进行改进。
我倾向于相信这种涌现能力(通过语言反馈进行自我改进)会对 LLM 研究产生非常重要的影响,因为这意味着 AI 可以在很少的人类监督下不断自主改进。」
方法
自修复概述
如上图 1 所示,自修复方法包括 4 个阶段:代码生成、代码执行、反馈生成和代码修复。接下来正式定义这四个阶段。
代码生成
给定一个规范 ψ,程序模型 M_P 首先生成 n_p 个独立同分布样本,研究者将其表示为
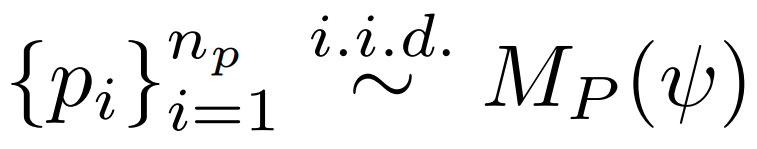
代码执行
然后在测试台上执行这 n_p 个代码样本。研究者假设可以访问可执行形式的全套测试,因此如果任何样本通过了所有测试,系统就会停止,因为这时已经找到了一个令人满意的程序。否则,系统将收集执行环境返回的错误消息。这些错误消息要么包含编译 / 运行时错误信息,要么包含程序输出与预期输出不同的示例输入。示例如图 1(组件 3)所示。
反馈生成
由于来自执行环境的错误消息通常非常高级,因此它们提供的修复信号很少。作为中间步骤,研究者使用反馈模型来更详细地解释出了什么问题;示例如图 1(组件 4)所示。形式上,在这个阶段,他们为每个错误的程序 p_i 生成 n_f 个反馈字符串,具体如下所示:
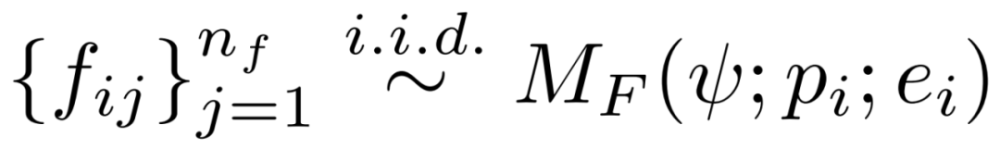
有了明确的反馈生成步骤,就可以消融这个组件,独立地研究它的意义。
代码修复
在最后一步中,对于每个初始程序 p_i 和反馈 f_ij,可以从采样 n_r 个候选修复程序:
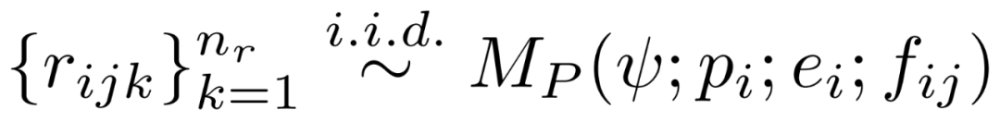
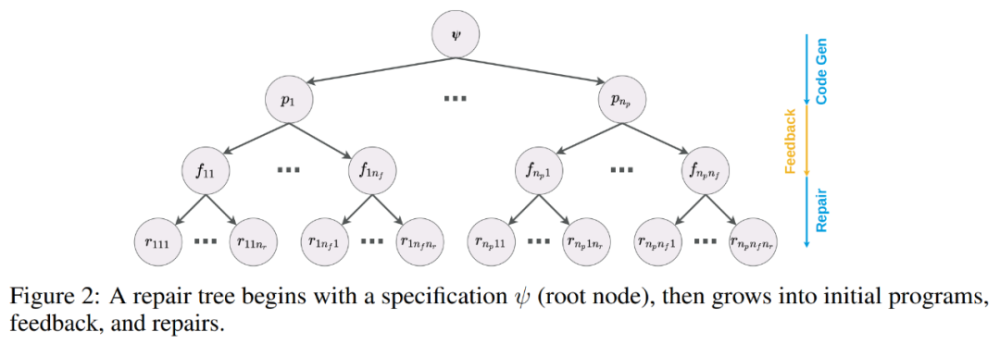
修复树。研究者将该过程生成的包含文本和程序的树称为植根于规范中的 ψ,然后分支到初始程序 p_i,每个初始程序分支到反馈 f_ij,然后对修复树 r_ijk 进行修复,如下图所示。
注意:联合采样反馈和修复。上述通用框架不要求编程模型和反馈模型相同,因此两个模型可以使用各自的专有模型。然而,当 M_P=M_F 时,研究者在单个 API 调用中联合生成反馈和修复的程序,因为 GPT-3.5 和 GPT-4 都有在响应中交织文本和代码的自然倾向。形式上,研究者将其表示为
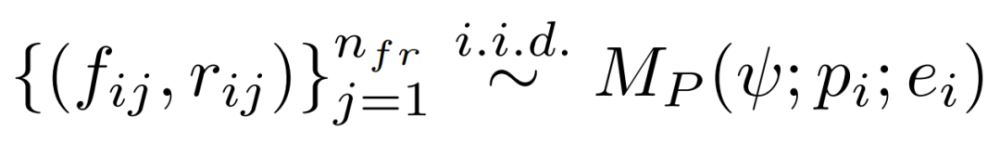
pass@t:通过率与 token 数量的关系
由于自修复需要几个非均匀成本的依赖模型调用,因此 pass@k 这种在 k 个独立同分布样本中获得正确程序的可能性指标,不是用于比较和评估自修复的各种超参数选择的合适度量。相反,研究者将通过率作为从模型中采样的 token 总数的函数,称之为 pass@t。
形式上,假设一个数据集 D=_d 和超参数(M_P,M_F,n_p,n_f,n_r)的一组选定值。令
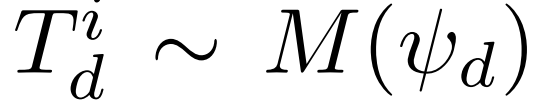
表示上文所述对任务 ψ_d 进行采样的修复树;令 size(T^i_d)表示修复树中的程序和反馈 token 的总数;并在当且仅当 T^i_d 至少有一个叶子节点程序满足规范中的单元测试 ψ_d 时,令 T^i_d |=ψ_d 为真。然后 pass@t 这种超参数选择的度量被定义为希望通过这种超参数选择生成的 token 数量时预期通过率:
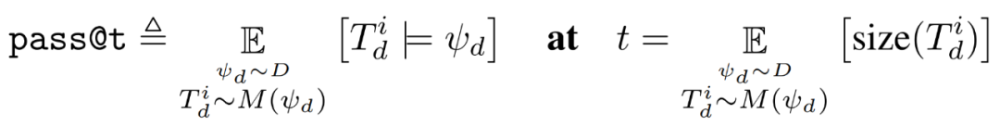
实验绘制了这两个量的 bootstrapped estimates(一种统计估计方法,通常用于评估参数估计的不确定性)。为了获得这些数值,本文首先为每个任务规范生成一个非常大的修复树,其中:有 N_p≥n_p 个初始程序样本;每个错误程序有 N_f≥n_f 个反馈字符串;并且每个反馈串有 N_r≥n_r 个修复候选。给定(n_p,n_f,n_r)的设置,然后从这个冻结的数据集中对 N_t 个不同的修复树进行子采样(带替换)。最后,本文计算了这 N_t 棵树上通过率和树大小的样本均值和标准差。如此估计 pass@t 大大降低了实验的计算成本,因为可以重用相同的初始数据集来计算 n_p、n_f 和 n_r 的所有不同选择的估计。
本文所有实验中,N_p=50,自修复方法中 n_p≤25,基线无修复方法中 n_p≤50。类似地,对于反馈,本文令 N_f=25 和 N_f≤10。对于候选修复,由于本文在大多数实验中对反馈和修复进行联合采样,因此本文设置 N_r=n_r=1。最后,本文对所有设置使用 N_t=1000。
实验
研究者针对以下问题进行了相关实验:
(a)在具有挑战性的编程难题的背景下,对于本文提出的模型,自修复是否比不修复的独立同分布采样更好?如果是,在什么超参数下自修复最有效?
(b) 更强的反馈模型会提高模型的修复性能吗?
(c) 即使是最强的模型,让人参与提供反馈会带来更好的修复性能吗?
本文使用 APPS 数据集评估了这些关于 Python 编程挑战的疑惑。
自修复需要强大的模型和多样化的初始样本
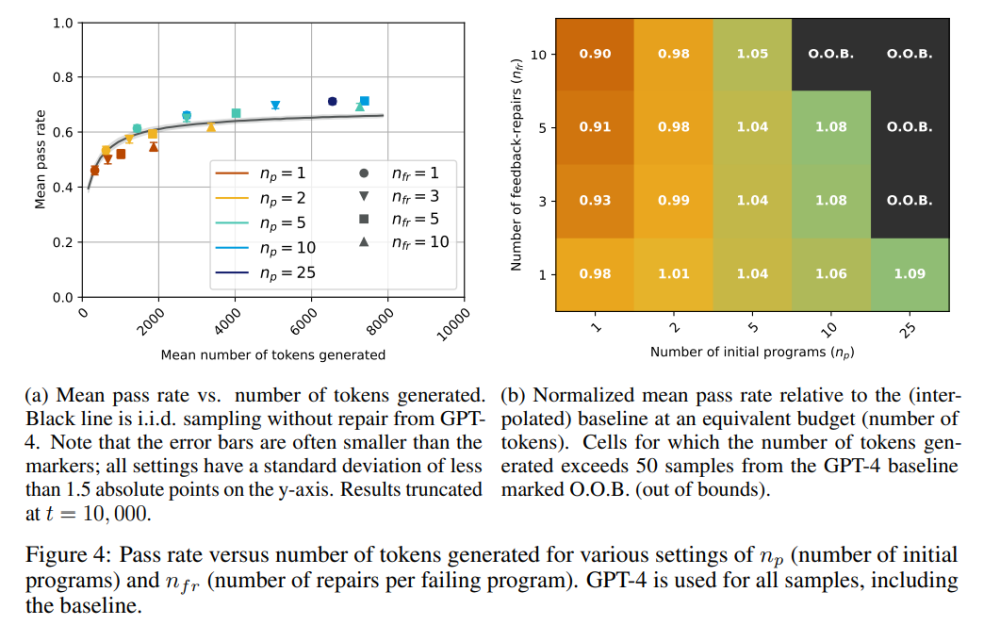
令 M_P=M_F∈,用于代码 / 修复生成和反馈生成的是同一个模型。GPT-3.5 的结果见图 3,GPT-4 的结果见图 4。
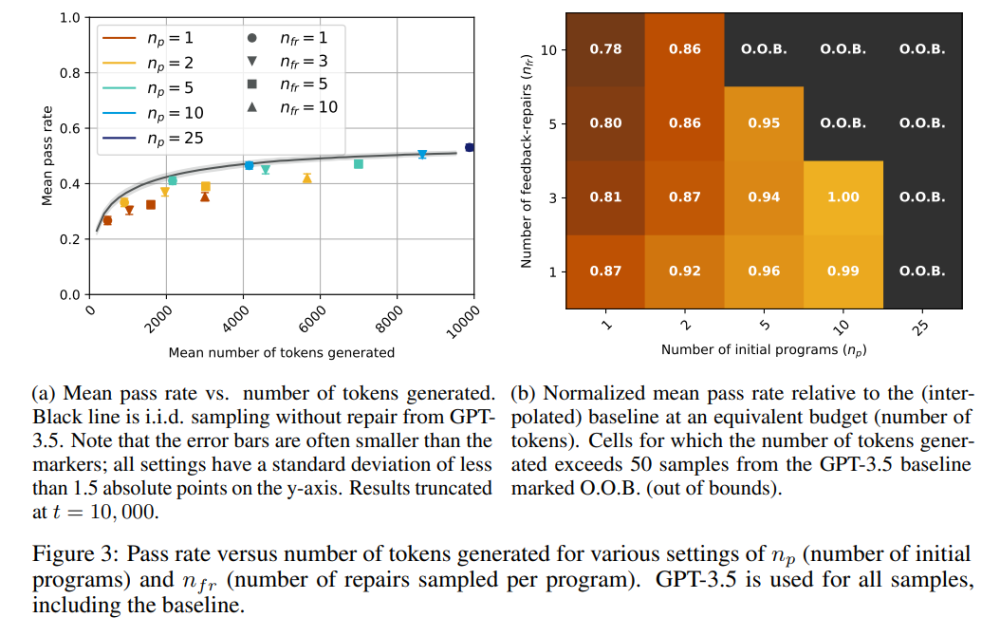
从图中可以看出,对于 GPT-3.5 模型,pass@t 在所有的 n_p、n_fr 选值中,都低于或等于相应基线(黑线),这清楚地表明自修复不是 GPT-3.5 的有效策略。另一方面,对于 GPT-4,有几个 n_p、n_fr 值,其自修复的通过率明显优于基线的通过率。例如,当 n_p=10,n_fr=3 时,通过率从 65% 增加到 70%,当 n_p=25,n_fr=1 时,通过率从 65% 增加至 71%。
GPT-4 的反馈改进了 GPT-3.5 自修复能力
接下来,本文进行了一个实验,在这个实验中,研究者评估了使用一个单独的、更强的模型来生成反馈的影响。这是为了检验一种假设:即模型无法内省和调试自己本身的代码,从而阻碍了自修复(尤其是 GPT-3.5)。
该实验的结果如图 5 所示(亮蓝线)。研究者观察到,就绝对性能而言,M_P=GPT-3.5,M_F=GPT-4 确实突破了性能障碍,变得比 GPT-3.5 的独立同分布采样效率略高。这表明反馈阶段至关重要,改进它可以缓解 GPT-3.5 自修复的瓶颈。
人类反馈显著提高了 GPT-4 自修复的成功率
在本文的最后一个实验中,研究者考虑了在使用 GPT-4 等更强的模型进行修复时使用专业人类程序员的反馈的效果。这项研究的目的不是直接比较人在循环中的方法与自修复方法,因为人在循环方法会带来更多的认知负担,而本文没有对此进行研究。相反,本文的目标是了解模型识别代码中错误的能力与人类相比如何,以及这如何影响自修复的下游性能。因此,该研究对人类反馈对自修复的影响进行了定性和定量分析。
结果总结在表 1 中。我们首先注意到,当我们用人类参与者的调试取代 GPT-4 自己的调试时,总体成功率提高了 1.57 倍以上。也许不足为奇的是,随着问题变得越来越困难,相对差异也会增加,这表明当任务(和代码)变得更加复杂时,GPT-4 产生准确和有用反馈的能力远远落后于我们的人类参与者。
此外,该研究还定性地分析了人类参与者提供的反馈与 GPT-4 提供的反馈之间的差异。
只有 2/80 个人贡献的反馈字符串包括伪代码或显式 Python;也就是说,获得的几乎所有人类反馈都是自然语言,偶尔穿插着单语句数学 / 代码表达式。
GPT-4 的反馈更可能明显不准确(32/80 与人类反馈的 7/80)。
GPT-4 更可能明确地建议小的变化(54/80 对 42/80;28/48 对 38/73,当看起来正确时),而我们的人类参与者显示出更大的趋势来建议高水平的变化(23/80 对 18/80,GPT-4;21/73 对 13/48,当看起来正确时)。
人类参与者有时会表达不确定性(7/80);GPT-4 没有(0/80)。
进一步的分析表明,表 1 中的结果不是由于人为因素造成的,例如参与者提供了模型简单复制的显式代码块。相反,性能的差异似乎是由更准确的反馈、在需要时建议对代码进行高级别、大规模更改的更大能力,以及参与者表达其不确定性的能力(而不是自信地给出潜在的不准确反馈)共同造成的。