尽管内向外追踪的性能已经足以在头显、控制器和双手追踪方面取代外向内追踪,但由于视场覆盖问题,全身动捕一直以来都是依靠外向内的追踪设置来实现。不仅只是这样,随着头显形状参数的不断小型化轻薄化,摄像头的视场覆盖问题将会变得越发困难。
不过,社区依然在积极探索利用AI等手段来提供下半身的姿态估计。实际上,如果你有留意映维网的专享,诸如Meta,卡内基·梅隆大学,苏黎世联邦理工学院等已经发布了各种论文研究。
现在,韩国首尔大学和Meta的研究人员日前又发布了一项相关研究。利用头显+控制器的组合,以及算法技巧,团队提供了一种名为QuestEnvSim的解决方案。
为了实现真正的临场感,用户的Avatar必须准确地复刻肢体动作和肢体语言,并实现与环境的自然交互。基于标记的追踪方案繁琐和昂贵。
首尔大学和Meta团队的目标是创建一个只依赖于消费者VR设备的姿态和环境信息作为输入的追踪方案,例如头显+控制器。
从稀疏传感器合成全身运动具有挑战性,因为诸多不同的姿态都可能符合给定的传感器输入,从而造成不准确的估计,尤其是下半身。另外,生成合理的对象交互运动需要特别注意。例如,当用户与他们的环境交互时(坐在沙发上或靠在桌子),这引入了复杂的物理约束。而且下半身并不总是完全受到平衡的约束,所以存在更多的模糊性。例如,当坐在沙发时,诸多不同的姿态都可能符合给定的传感器输入,所以造成不准确的估计。
在名为《QuestEnvSim: Environment-Aware Simulated Motion Tracking from Sparse Sensors》的论文中,团队开发了一种将头显和控制器姿态以及环境的表示作为输入,并生成与传感器输入及其周围环境相匹配的全身运动的运动追踪算法。
具体地说,团队使用物理模拟的Avatar,并通过深度强化学习学习控制策略来产生扭矩以驱动Avatar,目标是尽可能接近地追踪用户的头显和控制器姿态。
当然,社区已经提出了多种类似于所述方法的基于物理Avatar的运动追踪系统。但研究人员认为,对于特定方法,除了脚-地板接触之外,它们尚未证明其他环境交互。至于其他方法,它们采用人工力来处理复杂的接触动力学,而这会产生不自然的运动。
首尔大学和Meta不是使用人工力量,他们的控制策略训练成积极地使用环境来产生适当的外部力量来驱动模拟Avatar,而其中的策略是从包括环境交互的动捕数据中学习。所以,系统产生的动作在物理上是准确的,在环境中更可信。例如,如果头戴式显示器靠近椅子,这可能意味着用户已经坐了下来,而不是仅仅处于蹲伏的状态。
研究人员首先证明了稀疏上半身输入。如果与物理模拟和环境观察相结合,其可以在高度受限的环境中产生真实的全身运动,无需使用任何人工力。
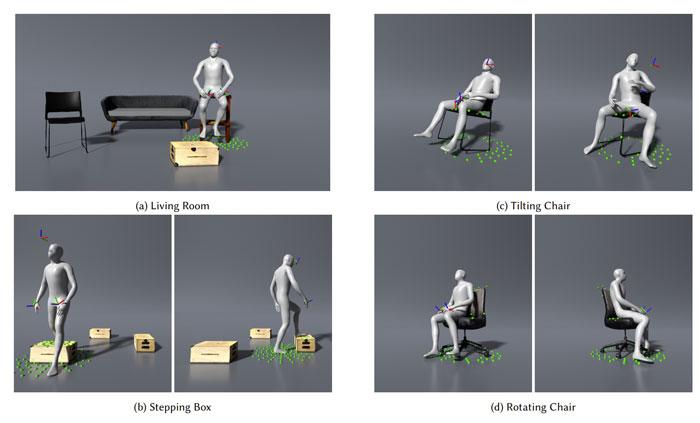
为了展示系统的能力,研究人员展示了各种各样的例子,比如坐在椅子、沙发和盒子、踏过盒子、摇椅子和转动办公椅等等。其中,所有的动作都是由真实用户输入产生,不使用任何后处理,例如逆运动学、接触解析和平滑等。
当然,如果你留意上面的视频,你依然会发现由于摄像头视场覆盖问题,以及诸多不同的姿态都可能符合给定的传感器输入,所以QuestEnvSim依然无法准确估计微妙的下半身姿态,尤其是视频后半段,你会多次发现下半身的姿态估计不完全准确。
相关论文:QuestEnvSim: Environment-Aware Simulated Motion Tracking from Sparse Sensors
不过,研究人员相信这是稀疏传感器与场景交互的运动追踪所取得的最高质量结果之一。接下来,团队将继续努力,并不断优化解决方案。