Meta 发布语音生成 AI 模型 Voicebox
近日,Meta AI 宣布在生成式 AI 语音模型领域取得了突破:开发出了首个可泛化至多种语音生成任务的模型 Voicebox,无需专门训练即可达成顶尖性能表现。Meta AI 研究人员分享了多段音频样本和一篇研究论文,其中详细介绍了他们采用的方法和取得的成果。
与图像及文本类生成系统一样,Voicebox 能够创建多种样式的输出,包括从零开始创建输出、修改给定样本等。但与以往不同的是,Voicebox 并非简单创建图片或一段文字,而是直接生成高质量的音频片段。该模型能够为括英语、法语、西班牙语、德语、波兰语和葡萄牙语在内的六种语言合成语音,同时执行噪声去除、内容编辑、风格转换和多样化样本生成等任务。
在 Voicebox 出现之前,生成式 AI 语音模型需要配合精心准备的训练数据,就各项任务接受特定训练。Voicebox 使用一种新的方法,可直接从原始音频和随附的转录结果中学习。与只能根据给定音频片段续写结尾的自回归模型不同,Voicebox 能够修改给定样本中的任意部分。
据了解,Voicebox 能够出色执行各种任务,具体包括:
结合上下文的文本到语音合成:使用长度仅为两秒的输入音频样本,Voicebox 即可匹配样本的音频风格并据此进行文本到语音生成。后续项目有望为无法说话的人士提供语音支持,或者为游戏 NPC 及虚拟助手快速生成对话语音。
跨语言风格转换:给定一段语音样本,外加一段英语、法语、德语、西班牙语、波兰语或葡萄牙语的文本,Voicebox 即可生成对应的朗读音频。这种能力讼人兴奋,未来可以帮助使用不同母语的人们通过自然且真实的方式开展交流。
语音降噪与编辑:Voicebox 的上下文学习为其赋予了强大的语音生成能力,可无缝编辑音频中的片段。它能重新合成被暂时噪声干扰的语音部分,或者替换掉说错的词,而无需重新录制整段语音。用户可以找到语音中被噪声(如狗叫声)干扰的原始片段,剪切出来并指示模型重新生成。有朝一日,这种能力还可用于清洗和编辑音频,且使用过程与目前流行的图像编辑工具一样轻松便捷。
多样化语音采样:利用多样化的真实数据完成学习后,Voicebox 将可生成与人们的现实对话高度吻合的以上六种语言对话音频。未来,此功能可用于生成合成数据,协助提升语音助手模型的训练效果。研究结果表明,基于 Voicebox 生成的合成语音训练出的语音识别模型,在性能上几乎与使用真实语音的模型相当,错误率降低了 1%;与以往同类文本到语音模型相比,合成语音数据训练结果的错误率更是大幅降低 45%至 70%。
Voicebox 的诞生,标志着生成式 AI 研究又向前迈出了重要一步。在文本、图像和视频生成等方面,具备任务泛化能力的可扩展生成式 AI 模型已经激发了人们对于跨任务潜在应用的浓厚兴趣。Meta AI 希望音频领域未来也能掀起同样的潮流,同时继续保持深耕和探索,关注其他研究人员如何在 Voicebox 的基础之上寻求新的突破。
Voicebox 背后的 Flow Matching 技术
现有语音合成工具的主要局限之一,在于只能就专门的任务配合准备好的数据接受训练。这些单调而干净的输入数据相对有限且难以收集,因此也导致输出结果变得同样单调。
Meta AI 的研究人员基于“流匹配”(Flow Matching)技术构建了 Voicebox,这项技术是 Meta 在非自回归生成模型领域的最新进展,能够掌握文本到语音之间高度不确定的映射。非确定性映射非常重要,它使得 Voicebox 能够从不同的语音数据中学习,且无需对各种变化要素做详尽标注。也就是说,Voicebox 能够在多样性更强、规模更大的数据之上进行训练。
与当前最先进的英语模型 VALL-E 相比,Voicebox 在可懂度(即单词错误率,前者为 5.9%,Voicebox 为 1.9%)和音频相似度(0.580 对 0.681)方面均更加强大,且速度要快 20 倍。在跨语言风格迁移方面,Voicebox 也优于领先模型 YourTTS,能够将平均单词错误率从 10.9%降低至 5.2%,并将音频相似度从 0.335 提高至 0.481。
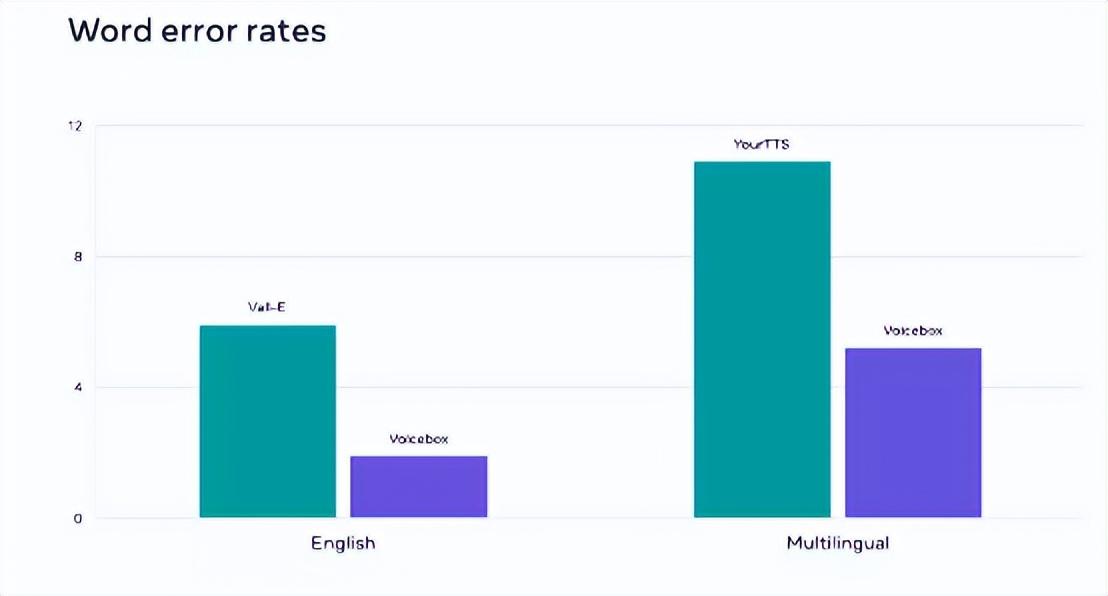
Voicebox取得新的先进结果,在单词错误率方面优于Vall-E和YourTTS。
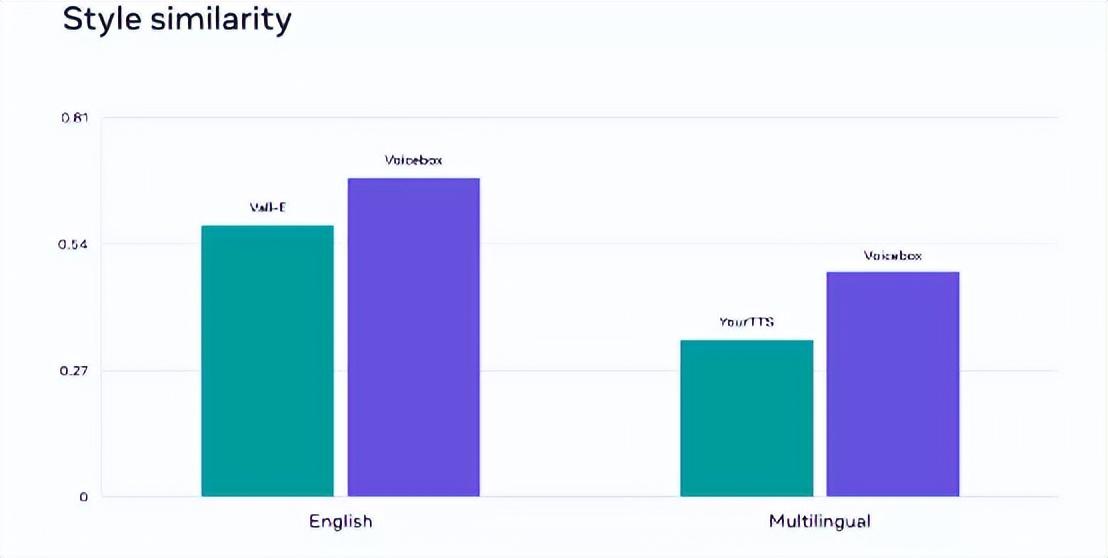
Voicebox还分别在英语和多语言基准测试中的音频风格相似性方面,达成了新的顶尖成绩。
研究人员使用超过 5 万小时的语音录音,和来自英语、法语、西班牙语、德语、波兰语和葡萄牙语的公共有声读物转录对 Voicebox 进行训练。经过训练后,Voicebox 能够在给定前后语音和片段转录数据时预测出语音片段。它还能学会根据上下文补全语音,从而被应用于其他语音生成任务,包括在无需重建整个输入的前提下生成音频的中间部分。
“AI 孙燕姿”爆火后,再看语音生成滥用风险
Voicebox 拥有众多令人兴奋的用例,但 Meta 也承认其存在潜在的滥用风险,所以 Meta AI 的研究人员决定暂不公开 Voicebox 模型或代码。Meta 在社交平台上公开表示:“与其他强大的人工智能创新技术一样,我们认为这项技术也可能会被滥用,造成意外伤害。”
事实上,语音生成引发的滥用风险并不少见。以华语乐坛最近爆火的“AI 孙燕姿”为例,AI 让孙燕姿翻红的同时,也让背后的风险显露出来。一方面,AI 合成声音可能涉及侵权问题,另一方面,也可能带来一系列伦理和法律的风险。
我国《民法典》第 1023 条第二款规定,对自然人声音的保护,参照适用肖像权保护的有关规定。第 1019 条第一款规定,任何组织或者个人不得以丑化、污损,或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意,不得制作、使用、公开肖像权人的肖像。由此可见,比照对肖像的人格权保护,未经权利人的同意,也不得制作、使用、公开利用权利人的声音。
此外,语音生成也会成为电信诈骗的利器。前段时间,美国和加拿大各地使用 AI 合成语音进行电信诈骗的案例多发,不少老年上当受骗。加拿大警方称,最近加拿大各地都有不少类似案件发生,涉案金额已达数百万加元。有受害者表示,犯罪分子使用的声音和她儿子的声音简直一模一样。在美国,类似的诈骗案件近期也呈上升趋势。
作为首个能够成功执行任务的多功能、高效泛化模型,Meta AI 坚信 Voicebox 即将开创生成式 AI 语音模型的新时代,但与其他强大的 AI 创新成果一样,这项技术同样可能因误用引发意外危害。对于语音生成带来的滥用风险,Meta 也想好了对策——构建一款高效分类器,用以区分由 Voicebox 生成的音频和真实语音,借此缓解未来可能出现的种种风险。
在论文(https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/)中,Meta AI 研究人员还具体讲解了如何构建一款高效分类器,用以区分真实语音和 Voicebox 生成的音频。
参考链接:
https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
http://www.xinhuanet.com/ent/20230620/85f213fc8b914b7a9ea17addc3cec01e/c.html
本文转载来源:
https://www.infoq.cn/news/YF1LRfH3Ttt7eZ0mBPjQ