Meta公司宣布了一个新的开源人工智能模型,将多个数据流联系在一起,包括文本、音频、视觉数据、温度和运动读数。该模型目前只是一个研究项目,没有直接的消费者或实际应用,但它指出了生成性人工智能系统的未来,可以创造沉浸式的多感官体验,并表明在OpenAI和Google等竞争对手变得越来越神秘的时候,Meta继续分享人工智能研究。
该研究的核心概念是将多种类型的数据连接起来,形成一个单一的多维指数(或"嵌入空间",用人工智能的说法)。这个想法可能看起来有点抽象,但正是这个概念支撑着最近生成性人工智能的蓬勃发展。
例如,像DALL-E、Stable Diffusion和Midjourney这样的人工智能图像生成器都依赖于在训练阶段将文本和图像联系起来的系统。他们在视觉数据中寻找模式,同时将这些信息与图像的描述联系起来。这就是使这些系统能够按照用户的文字输入生成图片的原因。许多以同样方式生成视频或音频的人工智能工具也是如此。
Meta公司说,其模型ImageBind是第一个将六种类型的数据结合到一个单一的嵌入空间的模型。该模型包括的六种数据是:视觉(图像和视频形式);热能(红外图像);文本;音频;深度信息;以及最有趣的--由惯性测量单元或IMU产生的运动读数。(IMU存在于手机和智能手表中,它们被用于一系列任务,从将手机从横向切换到纵向到区分不同类型的身体活动)。
Meta博客文章中的一张截图,显示了不同类型的链接数据,例如,火车的图片、火车鸣笛的音频,以及关于火车三维形状的深度信息。
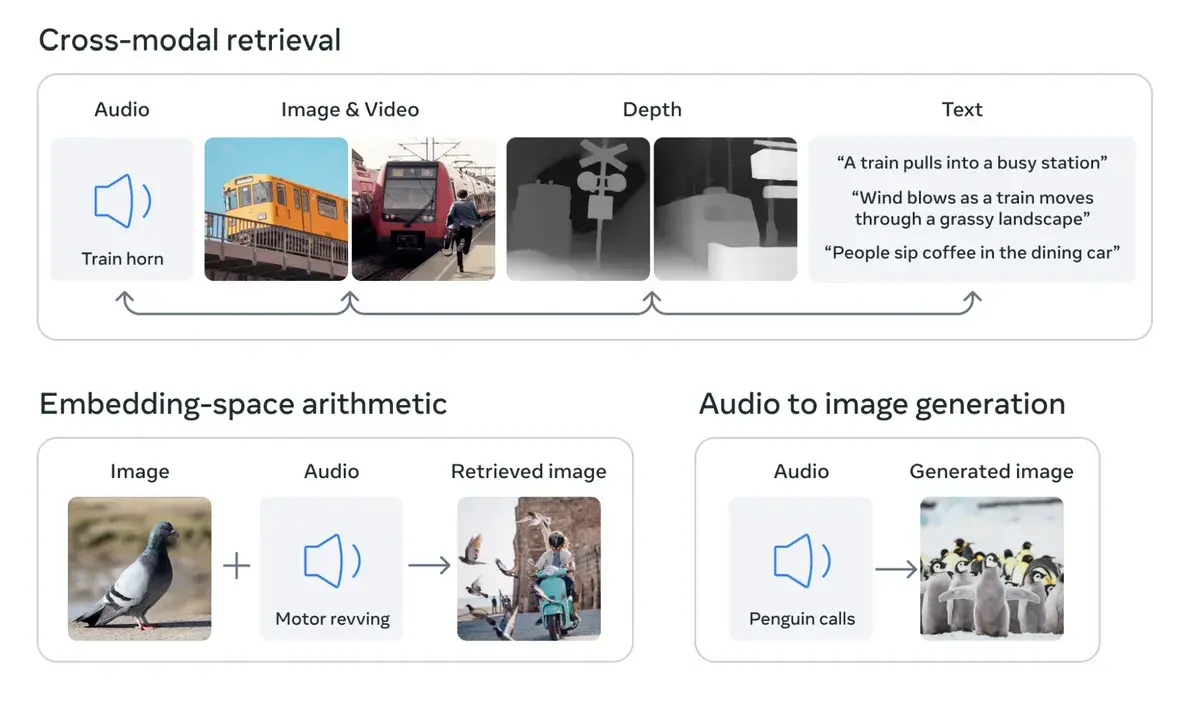
Meta的ImageBind模型结合了六种类型的数据:音频、视觉、文本、深度、温度和运动。
我们的想法是,未来的人工智能系统将能够交叉引用这些数据,就像目前的人工智能系统处理文本输入一样。例如,想象一下,一个未来的虚拟现实设备不仅能产生音频和视觉输入,还能产生你在物理舞台上的环境和运动。你可能会要求它模拟一次漫长的海上航行,它不仅会把你放在一艘船上,背景是海浪的噪音,而且还有甲板在你脚下的摇晃和海洋空气的凉风。
在一篇博文中,Meta公司指出,其他的感官输入流可以被添加到未来的模型中,包括"触摸、语言、气味和大脑fMRI信号"。它还声称这项研究"使机器离人类同时、全面和直接从许多不同形式的信息中学习的能力更近了一步"。
当然,这都是非常推测性的,而且像这样的研究的直接应用很可能会更有限。例如,去年,Meta公司展示了一个人工智能模型,可以从文本描述中生成短小而模糊的视频。像ImageBind这样的工作显示了该系统的未来版本如何纳入其他数据流,例如,生成音频以匹配视频输出。
不过,对于行业观察者来说,这项研究也很有趣,因为Meta公司正在开放底层模型--这是人工智能世界中越来越受到关注的做法。
那些反对开源的人,比如OpenAI说这种做法对创作者有害,因为对手可以复制他们的作品,而且这可能有潜在的危险,让恶意的行为者利用最先进的人工智能模型。倡导者回应说,开放源代码允许第三方仔细检查系统的缺陷,并改善它们的一些缺陷。他们指出,这甚至可以提供商业利益,因为它基本上允许公司招募第三方开发人员作为无偿工人来改进他们的工作。
到目前为止,Meta一直坚定地站在开源阵营中,尽管并非没有困难。(例如,其最新的语言模型LLaMA今年早些时候在网上泄露了。) 在许多方面,它在人工智能方面缺乏商业成就(该公司没有可以与Bing、Bard或ChatGPT匹敌的聊天机器人),这使得这种做法成为可能。同时,通过ImageBind,它正在继续实施这一战略。